
imhamburger 님의 블로그
데이터엔지니어 부트캠프 - FastAPI로 파일 업로드 기능 구현하고 파일을 업로드할 때마다 DB에 저장시키기 1탄 (11주차) 본문
데이터엔지니어 부트캠프 - FastAPI로 파일 업로드 기능 구현하고 파일을 업로드할 때마다 DB에 저장시키기 1탄 (11주차)
imhamburger 2024. 9. 22. 16:52MNIST 딥러닝을 시작하기 전에 사전 작업으로 파일을 업로드하면 해당 파일을 업로드할 때마다 DB에 저장시키는 기능을 구현하였다.
이전에는 텍스트만 입력하면 입력한 텍스트를 DB에 저장시키는 기능을 구현하였었다. (이전글)
1. 업로드 API 구현하기
이번엔 조금 업그레이드하여 파일을 업로드할 수 있는 기능을 구현해보자!
아래 코드는 FastAPI 공식문서를 참조하여 작성하였다. FastAPI에서는 다양한 기능을 간단하게 구현할 수 있어 편리하다.
from typing import Annotated
import os
from fastapi import FastAPI, File, UploadFile
from datetime import datetime
import pymysql.cursors
app = FastAPI()
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
#파일 저장
img = await file.read()
file_name = file.filename
upload_dir = "/Users/seon-u/photo"
file_full_path = os.path.join(upload_dir, file_name)
with open(file_full_path, 'wb') as f:
f.write(img)
return {
"filename": file.filename,
"content_type": file.content_type,
"file_full_path": file_full_path,
"time": datetime.now()
}
await란?
Python의 비동기 프로그래밍에서 사용되는 키워드이다.
위 코드에서 file.read()는 시간이 걸릴 수 있는 비동기 작업인데, await를 사용하면 이 작업이 끝날 때까지 기다렸다가 다음 줄로 넘어가게 된다.
즉, 프로그램이 파일을 다 읽을 때까지 기다린 후 return값을 할당한다.
await를 사용하는 함수는 반드시 async로 선언된 함수 안에서만 사용 가능하다.
결과
이미지 파일 하나를 업로드하였다.
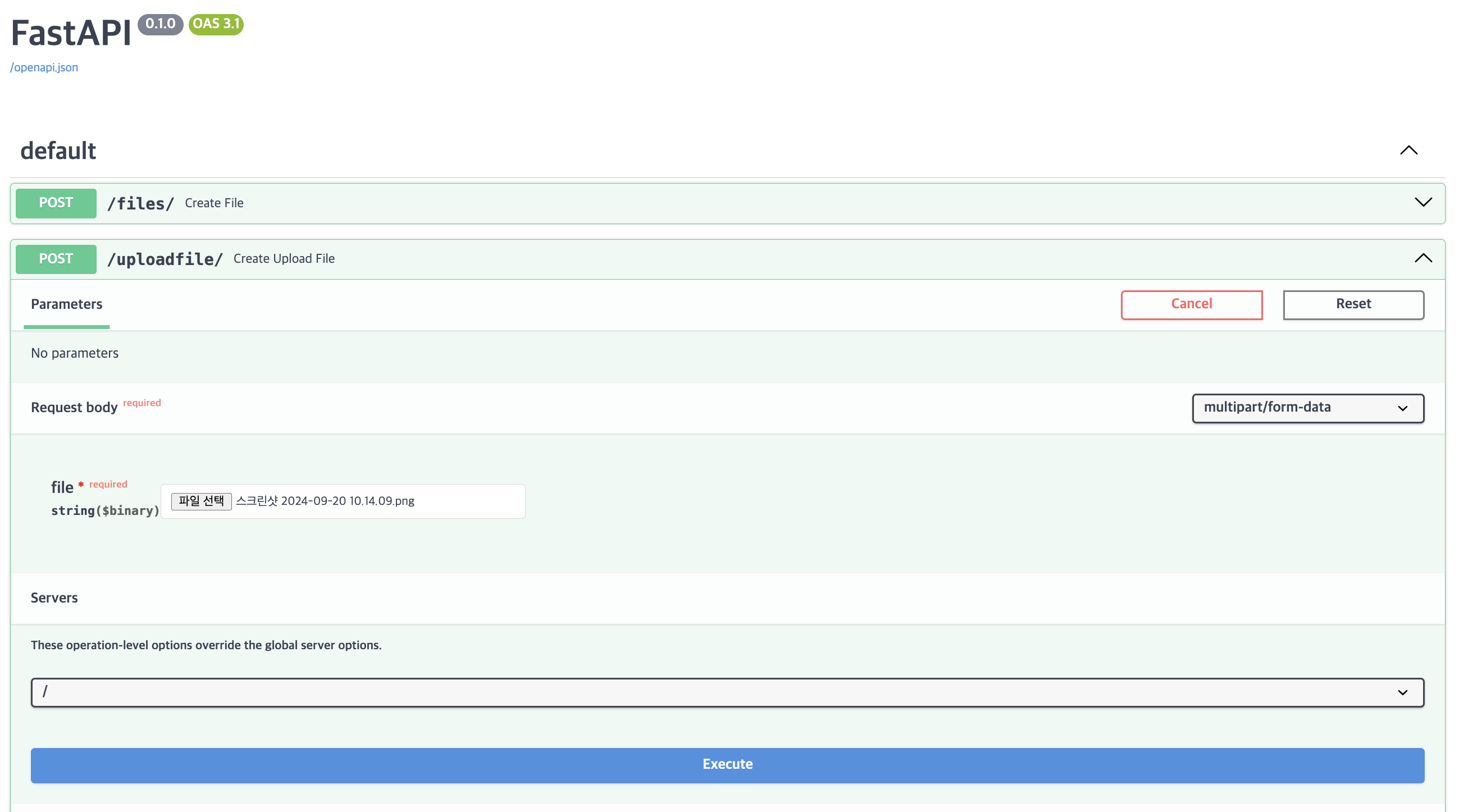
지정한 경로에 저장되었는지 파일을 확인하니 정상적으로 저장이되어있었다.
2. DB 준비하기
나는 MariaDB를 Docker 허브에서 pull 받았다. 그리고 도커 허브에 올라와있는 MariaDB 문서를 참조하여 run 하였다.
docker run -d \
--name <컨테이너명 입력> \
-e MARIADB_USER=<생성할 DB 유저명 입력> \
--env MARIADB_PASSWORD=<비밀번호 입력> \
--env MARIADB_DATABASE=<생성할 데이터베이스명 입력> \
--env MARIADB_ROOT_PASSWORD=my-secret-pw \
-p <포트번호>:3306 \
mariadb:latest
포트번호는 53306으로 주었다.

그럼 다음 도커 이미지에 들어가 mariadb에 접속한다.

다음은 테이블을 생성해준다.
CREATE TABLE image_processing (
num INT AUTO_INCREMENT PRIMARY KEY COMMENT '자동 증가 숫자',
file_name VARCHAR(100) NOT NULL COMMENT '원본 파일명',
file_path VARCHAR(255) NOT NULL COMMENT '저장 전체 경로 및 변환 파일명',
request_time VARCHAR(50) NOT NULL COMMENT '요청시간',
request_user VARCHAR(50) NOT NULL COMMENT '요청 사용자',
prediction_model VARCHAR(100) COMMENT '예측 사용 모델',
prediction_result VARCHAR(50) COMMENT '예측 결과',
prediction_time VARCHAR(50) COMMENT '예측 시간'
);
생성한 테이블 확인하기
MariaDB [mnistdb]> desc image_processing;
+-------------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------------+--------------+------+-----+---------+----------------+
| num | int(11) | NO | PRI | NULL | auto_increment |
| file_name | varchar(100) | NO | | NULL | |
| file_path | varchar(255) | NO | | NULL | |
| request_time | varchar(50) | NO | | NULL | |
| request_user | varchar(50) | NO | | NULL | |
| prediction_model | varchar(100) | YES | | NULL | |
| prediction_result | varchar(50) | YES | | NULL | |
| prediction_time | varchar(50) | YES | | NULL | |
+-------------------+--------------+------+-----+---------+----------------+
8 rows in set (0.013 sec)
3. API 기능을 DB에 연결시키기
DB도 준비되었으니 이제 pymysql을 이용하여 위에서 만든 DB 정보를 입력하고 연결시켜주면 된다.
pymysql은 별도로 설치해주어야 한다. 설치방법과 사용방법은 여기를 참고!
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
img = await file.read()
file_name = file.filename
file_ext = file.content_type.split('/')[-1]
upload_dir = "/Users/seon-u/code/mnist/img"
if not os.path.exists(upload_dir):
os.makedirs(upload_dir)
import uuid
file_full_path = os.path.join(upload_dir, f'{uuid.uuid4()}.{file_ext}')
with open(file_full_path, 'wb') as f:
f.write(img)
connection = pymysql.connect(host="127.0.0.1",
user='mnist',
password='<비밀번호 입력>',
database='mnistdb',
port=int(53306),
cursorclass=pymysql.cursors.DictCursor)
sql = "INSERT INTO image_processing(`file_name`, `file_path`, `request_time`, `request_user`) VALUES(%s,%s,%s,%s)"
import jigeum.seoul #시간모듈
with connection:
with connection.cursor() as cursor:
cursor.execute(sql, (file.filename, file_full_path, jigeum.seoul.now(), 'n01'))
connection.commit()
return {
"filename": file.filename,
"content_type": file.content_type,
"file_full_path": file_full_path,
"time": jigeum.seoul.now()
}- pymysql.connect: MySQL 데이터베이스에 연결하는 함수
- host="127.0.0.1": 데이터베이스 서버가 로컬에서 실행되고 있다는 것을 의미 (나는 도커로 mariaDB를 실행시켰기 때문에 도커 IP 를 넣어야 했다.)
docker IP주소 확인
docker inspect <container ID>
docker inspect <container ID> | grep "IPAddress"
- user='mnist': 데이터베이스에 연결할 때 사용할 사용자 이름
- password='<비밀번호 입력>': 데이터베이스에 접근하기 위한 비밀번호
- database='mnistdb': 접속할 데이터베이스의 이름
- port=int(53306): 데이터베이스 서버에 연결할 때 사용할 포트 번호 (나는 도커로 53306으로 run하여서 53306으로 주었다.)
- cursorclass=pymysql.cursors.DictCursor: 결과를 딕셔너리 형태로 반환하는 커서를 사용. 즉, 데이터베이스에서 조회한 결과를 열 이름으로 접근할 수 있다.
- sql: SQL INSERT 문. image_processing 테이블의 file_name, file_path, request_time, request_user라는 4개의 필드에 데이터를 삽입. 참고로 %s는 실제 데이터가 들어갈 자리이다. 총 4개의 필드에 데이터를 삽입하니까 %s도 4개를 주었다.
with connection: 블록 사용
with connection:
이 with 블록 안에서 데이터베이스 작업을 수행하고, 블록을 벗어날 때 자동으로 연결을 종료한다.
커서 사용
with connection.cursor() as cursor:
connection.cursor(): 데이터베이스와 상호작용하기 위해 커서를 생성한다. 이 커서는 SQL 쿼리를 실행하는 데 사용된다.
SQL 쿼리 실행
cursor.execute(sql, (file.filename, file_full_path, jigeum.seoul.now(), 'n01'))cursor.execute(): sql 쿼리를 실행하고, 두 번째 인자로 전달된 튜플의 값들을 쿼리에 삽입한다.
예를들어, file.filename은 첫번째 필드인 file_name에 삽입된다.
마지막으로,
connection.commit(): 현재 트랜잭션을 커밋한다. 이는 데이터베이스에 영구적으로 변경 사항을 반영하는 작업이다.
INSERT 같은 데이터 변경 작업 후에는 반드시 커밋을 해야 한다.
그럼 DB에 연결시키는 건 끄읕!
근데 문제는 같은 이름의 파일을 동시에 여러번 업로드하면 한 개의 파일만 DB에 올라간다.
따라서 DB에 올라갈 때 같은 파일이라도 file_path를 고유값으로 주어 동시에 여러번해도 다 올라오게끔 해야한다.
그럴땐 파이썬 내장 라이브러리인 uuid를 써서 고유한 문자?들을 만들면 된다.
import uuid
file_full_path = os.path.join(upload_dir, f'{uuid.uuid4()}.{file_ext}')
결과

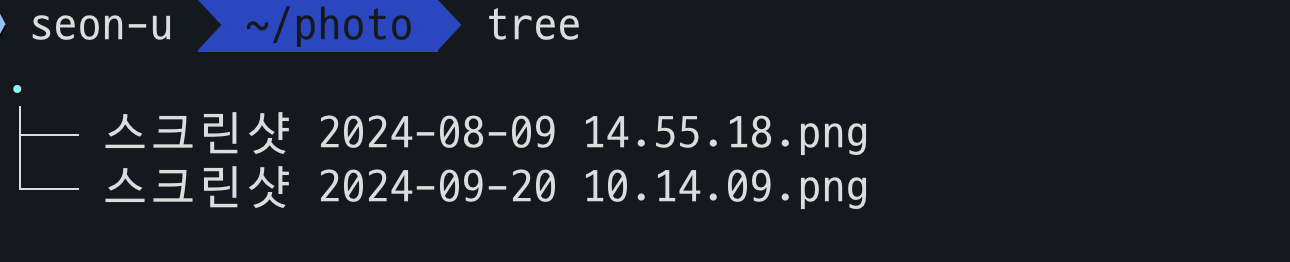
동시에 여러번을 업로드해도 DB에 잘 저장이 된다.
4. 아키텍쳐 설계하기
이대로 끝내면 좋겠지만, 조금 더 효율적인 기능을 위해 DB관련한 파일 따로, API기능 따로 분리한 아키텍쳐를 설계해보자.
이를 통해 코드의 재사용성을 높이고, 변경 사항이 발생했을 때 코드 관리가 더 쉬워지니 유지보수에 좋다.
/project_root
/db
db.py # 데이터베이스 관련 로직
/api
main.py # API 관련 로직
/worker
worker.py # 추후 딥러닝 모델을 위한 로직
나는 db.py, main.py, worker.py 총 3개로 분리해줄 것이다.
db.py
import pymysql.cursors
def get_conn():
conn = pymysql.connect(host="127.0.0.1",
user='mnist',
password='<비밀번호>',
database='mnistdb',
port=53306,
cursorclass=pymysql.cursors.DictCursor)
return conn
def select(query:str, size= -1):
conn = get_conn()
with conn:
with conn.cursor() as cursor:
cursor.execute(query)
result = cursor.fetchmany(size)
return result
def dml(sql, *values):
conn = get_conn()
with conn:
with conn.cursor() as cursor:
cursor.execute(sql, values)
conn.commit()
return cursor.rowcount
main.py
from typing import Annotated
import os
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/uploadfile/")
async def create_upload_file(file: UploadFile):
#파일 저장
img = await file.read()
file_name = file.filename
file_ext = file.content_type.split('/')[-1]
upload_dir = "/Users/seon-u/code/mnist/img"
if not os.path.exists(upload_dir):
os.makedirs(upload_dir)
import uuid
file_full_path = os.path.join(upload_dir, f'{uuid.uuid4()}.{file_ext}')
with open(file_full_path, 'wb') as f:
f.write(img)
sql = "INSERT INTO image_processing(`file_name`, `file_path`, `request_time`, `request_user`) VALUES(%s,%s,%s,%s)"
import jigeum.seoul
from mnist.db import dml
insert_row = dml(sql, file_name, file_full_path, jigeum.seoul.now(), 'n01')
return {
"filename": file.filename,
"content_type": file.content_type,
"file_full_path": file_full_path,
"time": jigeum.seoul.now(),
"insert_row_cont": insert_row
}
@app.get("/all")
def all():
from mnist.db import select
sql = "SELECT * FROM image_processing"
result = select(query=sql, size=-1)
return result
@app.get("/one")
def one():
from mnist.db import select
sql = """
SELECT *
FROM image_processing
WHERE prediction_time IS NULL
ORDER BY num
LIMIT 1"""
result = select(query=sql, size=1)
함수를 2개 더 추가하였는데 import하여 사용하니 코드의 가독성이 좋아졌다!
worker.py
아직 딥러닝 MNIST 모델을 만들지 않아 prediction_model / prediction_result / prediction_time 세 개의 컬럼이 NULL 값인 상태이다. 따라서 랜덤한 숫자를 넣어주려 한다. 추가적으로 라인알람을 설정해주었다.
import jigeum.seoul
import requests
import os
def run():
"""image_processing 테이블을 읽어서 가장 오래된 요청 하나씩을 처리"""
# STEP 1
# image_processing 테이블의 prediction_result IS NULL 인 ROW 1 개 조회 - num 갖여오기
from mnist.db import get_conn
from random import randrange
conn = get_conn()
with conn:
with conn.cursor() as cursor:
sql = "SELECT * FROM image_processing WHERE prediction_result IS NULL ORDER BY num"
cursor.execute(sql)
result = cursor.fetchall() #모든 행을 가져옴
# STEP 2
# RANDOM 으로 0 ~ 9 중 하나 값을 prediction_result 컬럼에 업데이트
# 동시에 prediction_model, prediction_time 도 업데이트
for i in result:
number = randrange(10)
num_id = i["num"] #key값
sql = f"""
UPDATE image_processing
SET prediction_result = {number},
prediction_model = {number},
prediction_time = '{jigeum.seoul.now()}'
WHERE num = {num_id}
"""
cursor.execute(sql)
conn.commit()
# STEP 3
# LINE 으로 처리 결과 전송
KEY = os.environ.get('API_TOKEN')
url = "https://notify-api.line.me/api/notify"
data = {"message": "성공적으로 저장했습니다!"}
headers = {"Authorization": f"Bearer {KEY}"}
response = requests.post(url, data=data, headers=headers)
print(response.text)
return True
랜덤숫자를 넣어주기 위해 random 모듈을 사용하였다.
이전의 NULL값인 행을 가져와 for문을 돌려 랜덤 숫자를 다 넣어주었다.
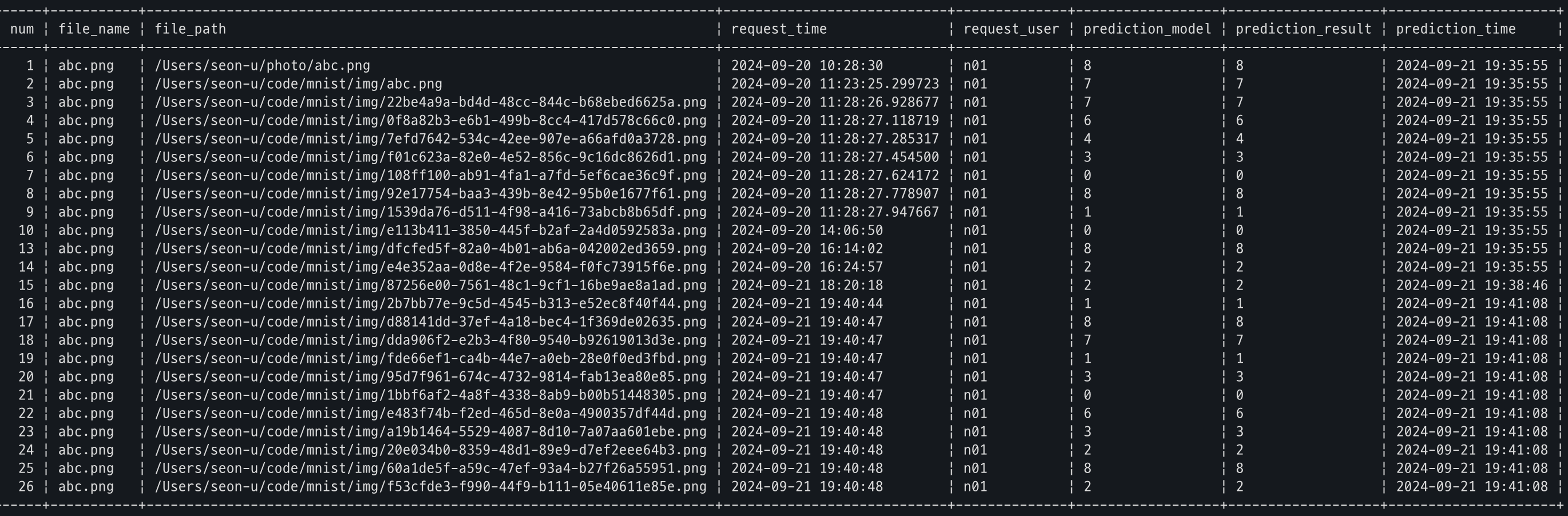
결과
랜덤 숫자를 넣어주기 전,
랜덤 숫자를 넣어준 후,
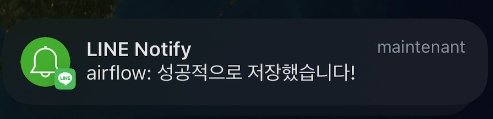
라인알람 결과 (예전에 airflow 때 썼던걸 재사용했더니 airflow 로 뜬다아....ㅋ)

일주일을 보내면서…
이번 주는 공모전 준비를 마무리하고 여유를 조금 되찾은 한 주였던 것 같다. 비록 아쉬운 부분이 남긴 하지만, 빅데이터 분석을 처음 접하면서 이론과 구현을 동시에 소화하는 것이 생각보다 어렵다는 것을 많이 느꼈다. 그래도 참여하는 데 의의를 두기로 했고, 그 과정에서 많은 것을 배웠다.
특히, 데이터 분석에서 전처리의 중요성을 절실히 깨달았다. 전처리가 잘못되면 처음부터 다시 해야 한다는 점에서 전처리 단계에 더 신경을 쓰게 되었다. 그리고 판다스 다루는 실력도 조금씩 나아지고 있다는 느낌이 든다. 공모전 관련 자료들은 완전히 다 끝나고 정리해두어야지.
앞으로 나의 방향
이제 부트캠프에 얼마 안남았다. 정말루... 근데 아직도 모르는 것 투성이이다. 이제 공모전도 끝났으니 다시 알고리즘 공부를 해야겠다. 알고리즘 문제를 풀 때도 종종 막히는 부분이 많아서 그럴 때마다 좌절하기보다는, 차근차근 다시 해봐야지. 예전에 비해 그래도 많이 나아졌으니, 너무 조급해하지 않으려고 한다.
파이썬과 데이터 분석에 대한 이해도는 조금씩 쌓이고 있지만, 그럼에도 여전히 부족한 부분들이 많다는 걸 느끼게 된다. 특히, 데이터를 다룰 때 어떻게 더 효율적으로 처리할지 고민이 필요하다. 이번에 배운 경험들을 바탕으로 부트캠프에서도 더 발전할 수 있도록 꾸준히 노력해야지!



