

imhamburger 님의 블로그
데이터엔지니어 부트캠프 - Regressor 회귀모델 구현하기 (10주차) 본문
1. Regressor (회귀 모델)
숫자를 예측하는 모델
어떻게 사용해?
예를 들어, 집값을 예측하고 싶다면 이 모델을 사용해. 집의 크기나 위치 같은 데이터를 주면, 그 데이터를 바탕으로 "이 집은 얼마일 것 같아"라는 숫자를 예측해준다.
예시: "이 집은 4억 원일 거야!" 또는 "내일 온도는 25도일 거야!" 같은 식으로 정확한 숫자를 예측하는 모델이다.
2. Classifier (분류 모델)
카테고리를 예측하는 모델
어떻게 사용해?
예를 들어, 어떤 이메일이 스팸인지 아닌지를 분류하고 싶다면, 이 모델을 사용해. 이메일의 내용을 보고 "이건 스팸이야" 또는 "이건 정상 메일이야"라는 식으로 분류해준다.
쉽게 예시: "이 사진은 고양이야!" 또는 "이 메일은 스팸이야!" 이렇게 카테고리를 정해주는 것이 분류 모델이다.
요약
Regressor는 "이 집은 얼마일까?"처럼 숫자를 예측하는 모델
Classifier는 "이 메일은 스팸일까?"처럼 종류를 예측하는 모델
그래서, 예측하려는 게 숫자면 Regressor, 카테고리나 종류면 Classifier를 쓰면 된다.
그러나!
회귀모델에는 한계가 있다.
농어의 길이를 입력하면 무게를 예측해주는 회귀모델을 구현해보자.
다음과 같은 농어 길이와 무게를 나타내는 array가 있다.
import numpy as np
perch_length = np.array(
[8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0]
)
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
이 표를 보기 편하게 표로 만들어보면 다음과 같다.
import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
회귀모델을 만들기 위해 훈련 데이터와 테스트 데이터를 각각 나누어 진행해야 한다.
데이터를 train(훈련)과 test(테스트)로 나누는 이유는 모델이 새로운 데이터를 잘 예측할 수 있는지 확인하기 위해서이다.
테스트 데이터(test data)는 모델이 학습한 후에 성능을 평가하는 데 사용하는데 중요한 점은, 학습된 모델이 테스트 데이터를 미리 보지 못했다는 것이다.
모델이 잘 배웠는지 확인하려면, 훈련에 사용하지 않은 데이터를 주고 새로운 데이터를 맞출 수 있는지 평가해봐야 한다.
테스트 데이터가 이 역할을 한다.
정리하자면,
훈련 데이터로만 모델을 평가하면, 모델이 그 데이터를 너무 잘 기억해서 테스트에서는 성능이 나빠질 수 있다.
새로운 데이터를 잘 맞추는지 확인하는 게 진짜 중요한 목표!!
그럼 train data와 test data를 내가 직접 나눠줘야해?
다행히도, 이를 나누어주는 모듈이 있다.
train_test_split 모듈을 사용하면 된다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
- length 와 weight 각각 56개의 데이터를 가지고 있는데 random_state에 값을 42로 준다면, train data는 42개로 test data는 14개로 나누어 준다.
- 이때, input은 length값이 들어가며 target은 weight 값이 들어간다. 왜냐하면 우리는 길이를 주면 무게를 예측해주는 모델을 만들기 위한 것이기 때문에
그럼 이제 준비는 다 마쳤고 학습을 시켜보자!
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
#학습
knr.fit(train_input, train_target)
바로 학습을 시켜주면 에러가 날 것이다.
우리의 데이터는 1차원 배열이기 때문이다. Regressor 회귀모델은 2차원 배열로 바꾸어주어야 한다.
왜?
scikit-learn에서는 입력 데이터를 항상 2차원 배열 형태로 받는다. 머신러닝 모델에서 입력 데이터는 각 샘플이 여러 특징을 가진 데이터로 취급되기 때문인데 예를 들어, 물고기의 길이만을 가지고 예측하는 경우라도 n개의 샘플과 각 샘플에 해당하는 1개의 길이 값을 포함하는 형태로 데이터를 만들어줘야 합니다.
1차원 배열 (잘못된 형식):
X = [50, 60, 70] # 샘플 3개, 특징이 1개인데 1차원 배열로 되어 있음.
2차원 배열 (올바른 형식):
X = [[50], [60], [70]] # 샘플 3개, 각 샘플에 특징(길이) 1개씩
1차원을 2차원으로 바꾸어주는 함수는 reshape를 사용하면 된다.
train_input = train_input.reshape(-1, 1)
test_input = test_input.reshape(-1, 1)
#출력
print(train_input.shape) #(42,1)
print(test_input.shape) #(14,1)
- reshape 안에 -1은 자동으로 크기를 맞추라는 뜻. numpy는 전체 원소 수가 변하지 않도록 남은 차원을 자동으로 계산
- 1은 배열의 두 번째 차원의 크기를 지정한 것.
- 더 자세한 설명은 해당 블로그를 참조!
그리고나서 다시 학습시켜주면 에러가 안날 것이다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
knr.fit(train_input, train_target)
이제 끝? 이라고 생각했지만 더 고려해주어야할 부분이 있다.
아까 위에서 test 데이터도 만들어줬었는데 정확성을 위해 학습시킨 데이터와 비교해보아야 한다.
점수를 한번 보자!
#좋은 모델은 score가 train이 test보다 더 높아야 한다.
print(knr.score(test_input, test_target))
print(knr.score(train_input, train_target))
#출력값
test : 0.992809406101064
train : 0.9698823289099254
점수가 test가 더 높다...
train 데이터의 점수를 더 높게 끌어올려야 한다. 그러기위해선 n_neighbors 수를 조정하면 된다.
n_neighbors 를 변수로 두고, 그래프를 그려보자.
x = np.arange(5, 45).reshape(-1, 1)
for k in [1, 3, 5, 7, 10, 15]:
knr.n_neighbors = k
knr.fit(train_input, train_target)
prediction = knr.predict(x)
#결정계수
s_train = knr.score(train_input, train_target)
s_test = knr.score(test_input, test_target)
plt.title(f'k={k}, R^2 = {s_train-s_test}')
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.show()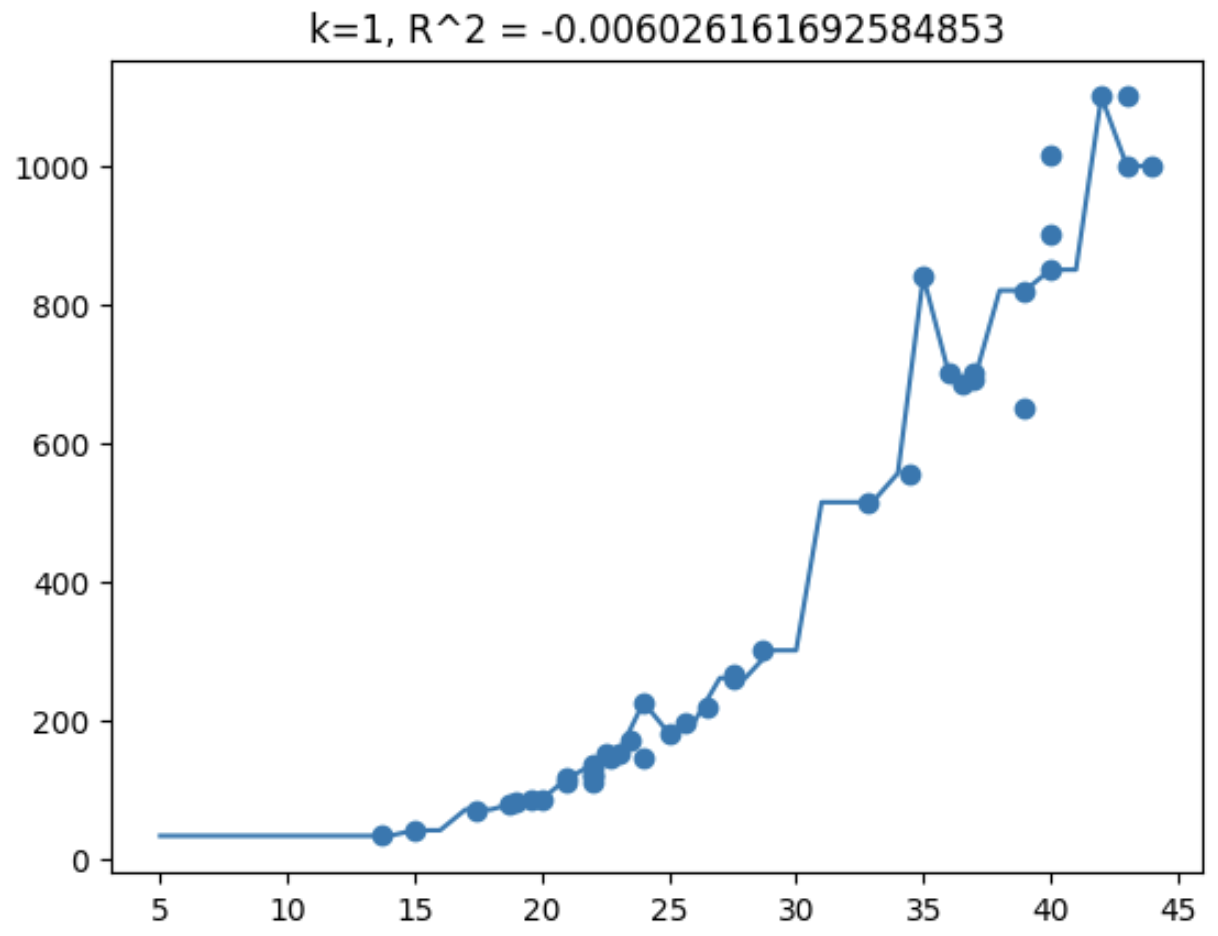





그래프를 살펴보니 n_neighbors가 3일 때가 예측값인 prediction이 train 데이터에서 input하였을 때 target값과 가장 가깝다.
그럼 n_neighbors=3을 적용해보자. (참고로 적용안하면 default 값이 5이다.)
knr.n_neighbors=3 #기본값은 5
knr.fit(train_input, train_target)
print(knr.score(train_input, train_target))
print(knr.score(test_input, test_target))
#출력값
train : 0.9804899950518966
test : 0.9746459963987609
train data의 점수가 더 높다!
이제 진짜 끝? 이라고 생각했는데....... 또 문제를 발견했다.
길이가 43이상이 되니 계속 같은 무게를 출력한다...
for i in range(42, 51):
prediction = knr.predict([[i]])
print(i, prediction)
#출력값
42 [1066.66666667]
43 [1033.33333333]
44 [1033.33333333]
45 [1033.33333333]
46 [1033.33333333]
47 [1033.33333333]
48 [1033.33333333]
49 [1033.33333333]
50 [1033.33333333]
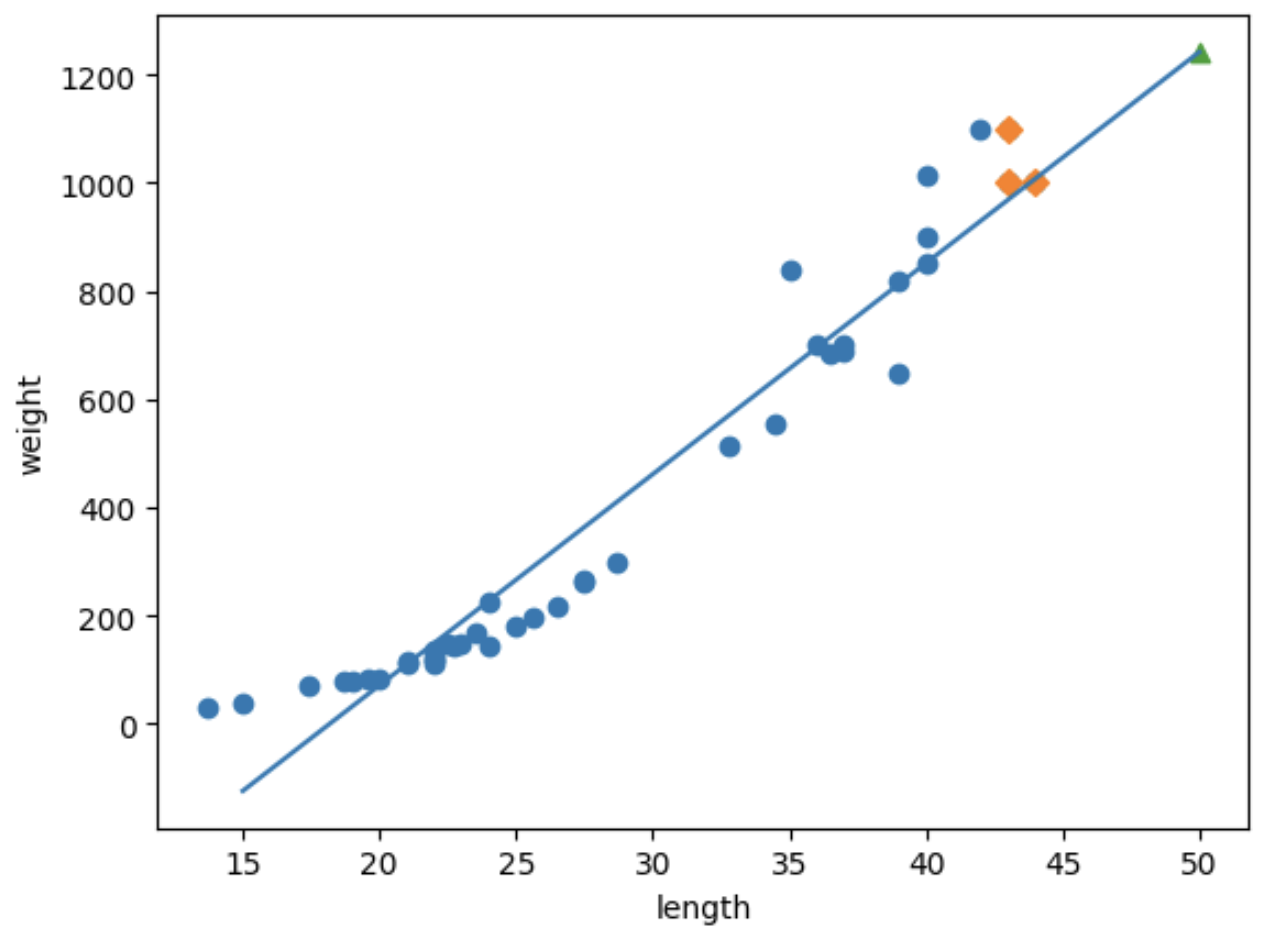
더 편하게 보기위해 그래프로 길이가 50이고 무게가 1241.8g 데이터를 '^'로 표시하고 그 주변 이웃들을 살펴보자.
distance, indexes = knr.kneighbors([[50]])
plt.scatter(train_input, train_target)
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()

위 그래프를 보면 길이가 50이여도 100이여도 모두 같은 이웃을 나타낸다. 이를 해결하기 위해선 선형회귀를 구현해야 한다.
선형회귀
선형회귀는 말 그대로 선형, 직선을 학습하는 알고리즘이다. 아래 그래프에서 보이는 직선의 모습대로 길이가 길어질수록 무게도 증가하게끔 만들어야 한다.
다행히도 선형회귀 직접 구현할 필요없이 이미 모듈이 있다. (만든사람 칭찬해...)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_input, train_target)
print(lr.predict([[50]]))
#출력값
[1241.83860323]
[1033.33333333] 이 아닌 [1241.83860323]로 예측하였다.
근데 어떻게 이런 값이 나왔지?
예전에 배웠던 수학을 기억해보자. 하나의 직선을 그리려면, 기울기와 절편이 있어야 한다.
y = ax + b
- 이 때 x는 농어의 길이(length)
- y는 농어의 무게(weight)
- a는 기울기 , b는 절편
근데 어떻게 기울기랑 절편값을 주지 않았는데 예측했지?
그 이유는 lr = LinearRegression() 에 lr객체에는 coef_ 와 intercept_ 속성이 저장되어 있다.
여기에서 lr.coef_는 기울기, lr.intercept_는 절편이다.
print(lr.coef_, lr.intercept_)
#출력값
[39.01714496] -709.0186449535477lr.coef_ (회귀 계수)
쉽게 말해서, 각 변수(특징)가 결과에 얼마나 영향을 미치는지를 나타내는 숫자.
예시: "집 크기가 1㎡ 커질 때마다 가격이 100만 원씩 오른다"는 의미라면, 그 100만 원이 바로 lr.coef_ 값.
lr.intercept_ (절편)
쉽게 말해서, 모든 변수(특징)가 0일 때, 결과가 시작하는 기준값. 즉, 아무 변화가 없을 때(예: 집 크기가 0㎡일 때) 결과가 얼마인지 보여준다.
예시: "집이 0㎡일 때 집값이 1000만 원이다"라는 의미라면, 그 1000만 원이 바로 lr.intercept_ 값.
(물론 현실적으로 0㎡ 집은 없지만, 모델에서는 기준값을 계산할 때 이 값을 사용.)
아까 위에서 보았던 선형(직선)을 코드로 쓰면, 다음과 같다.
distance, indexes = knr.kneighbors([[50]])
plt.scatter(train_input, train_target)
plt.scatter(train_input[indexes], train_target[indexes], marker='D')
plt.plot([15, 50], [15*lr.coef_+lr.intercept_, 50*lr.coef_ + lr.intercept_]) #직선
plt.scatter(50, 1241.8, marker='^')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
이제 다시 score를 확인해보면,
print(lr.score(train_input, train_target))
print(lr.score(test_input, test_target))
#출력값
train : 0.9398463339976041
test : 0.8247503123313559
점수가 둘 다 그리 높지 않다. 1점에 가까워야 정확도가 높은 것인데...
게다가 그래프 모양도 직선이라 농어의 무게가 0g 이하로 쭈욱 내려가는 것도 문제다. 현실에서는 무게가 0 이상일테니...
그리하여.....
다항회귀를 사용하여 0g으로 내려가는 저 직선을 곡선으로 바꿔주자. 아래처럼.

어떻게?
다항회귀를 사용하자.
다항회귀는 간단하게 말해서 다항식을 사용한 선형 회귀이다.
다항회귀
어렴풋이... 옛날에 배웠던 수학에서 2차 방정식을 이용하면 직선을 곡선으로 바꿀 수 있다는 것이 기억이 난다.
y = ax^2 bx + c
아까는 1차 방정식이었는데 2차 방정식의 그래프를 그리기 위해 길이를 제곱한 항이 train 데이터에 추가되어야 한다.
이 부분은 numpy를 이용하면 간단하게 만들 수 있다. np.column_stack
train_poly = np.column_stack((train_input ** 2, train_input))
test_poly = np.column_stack((test_input ** 2, test_input))
print(train_poly.shape, test_poly.shape)
#출력값
(42, 2) (14, 2)
짠! 길이를 제곱하여 추가했기 때문에 train data와 test data 모두 열이 2개로 늘어났다.
그리고 이를 다시 학습시켜준다.
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.predict([[50 ** 2, 50]]))
#출력값
[1573.98423528]
아까 전에 직선인 상태였던 것보다 더 높은 값을 예측했다.
그럼 train data와 test data의 점수를 평가해보자.
print(lr.score(train_poly, train_target))
print(lr.score(test_poly, test_target))
#출력값
train : 0.9706807451768623
test : 0.9775935108325122
아까보다 훨씬 점수가 높게 나왔다. 그렇지만 아직도 test 점수가 더 높다...!
조금 더 복잡한 모델이 필요할 것 같다... to be continued
직선 그래프와 마찬가지로 곡선도 그려보자.
우선.. lr.coef_와 lr.intercept_ 의 값을 알아야 한다.
print(lr.coef_, lr.intercept_)
#출력값
[1.01433211 -21.55792498] 116.0502107827827
그럼 2차방정식을 표현할 수 있다.
무게 = 1.01 * 길이^2 -21.6 * 길이 + 116.05
#구간별 직선을 그리기 위해 15에서 49까지 정수 배열을 만든다.
point = np.arange(10, 50)
#훈련 데이터의 산점도를 그린다.
plt.scatter(train_input, train_target)
#15에서 49까지 2차 방정식 그래프를 그린다.
plt.plot(point, 1.01*point**2 - 21.6 * point + 116.05) #곡선
#50cm 농어 데이터
plt.scatter(50, 1574, marker='*')
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
이 회귀모델을 저장하려면, pickle을 사용하면 된다.
# 회귀 모델 생성 및 훈련
lr = LinearRegression()
lr.fit(train_poly, train_target)
# 모델을 pickle을 사용해 저장
import pickle
with open('regression_model.pkl', 'wb') as f:
pickle.dump(lr, f)
뭔가 긴 여정이었다......... 이제 진짜 끄읕.....
일주일을 보내면서…
이번 주는 참 바쁘고? 어려운.. 것을 배운 한 주였다. 로드밸런서를 배우면서 다양한 서버의 부하 분산 방식을 실제로 적용해보는 시간을 가졌는데 아직 정확하게 이해가 되지 않았다. 또, Regressor 회귀모델도 새롭게 익히게 되었다. 이 과정에서 데이터 분석의 중요성과 머신러닝 모델을 활용한 예측의 기초를 다지는 데 많은 도움이 되었다. 특히 이번에 배운 내용은 공모전 준비를 하면서 큰 도움이 되었던 것 같다. 공모전에서 데이터를 분석하고 해석하는 능력은 필수적인데, 아직은 모든 과정을 능숙하게 다룰 수는 없지만 점차 익숙해지고 있다는 느낌을 받았다. 배울 것이 많았지만 그만큼 성취감도 느껴지는 한 주였다.
앞으로 나아갈 방향
사실 지금 가장 큰 바람은 공모전을 빨리 끝내는 것이다. 공모전 준비가 흥미롭기는 하지만, 긴장감 속에서 쉴 틈 없이 달려가는 느낌이라 빨리 마무리하고 싶다는 생각이 들기도 한다. 공모전이 끝나면 팀 프로젝트를 다시 시작해야 하지만, 그 전에 조금이라도 여유를 갖고 재충전할 시간이 있었으면 좋겠다. 개인적으로는 잠시나마 휴식을 취하며 다음 프로젝트에 더 나은 아이디어와 에너지를 가지고 임하고 싶다. 그러나 현실적으로 그럴 시간이 있을지는 잘 모르겠다. 계획대로라면 바로 다음 프로젝트로 넘어가야 하니까 말이다. 하지만 작은 여유라도 만들어낼 수 있기를 기대해본다.
이번 주를 되돌아보면 배운 것들이 많고 스스로의 성장을 느낄 수 있었던 만큼, 앞으로 더 나아갈 방향이 뚜렷해지는 것 같다. 앞으로는 배운 것들을 실전에서 더 자주 활용해보면서 자신의 능력을 더 키워나가는 것이 목표다.
'데이터엔지니어 부트캠프' 카테고리의 다른 글
| 데이터엔지니어 부트캠프 - FastAPI로 파일 업로드 기능 구현하고 파일을 업로드할 때마다 DB에 저장시키기 1탄 (11주차) (1) | 2024.09.22 |
|---|---|
| 데이터엔지니어 부트캠프 - API에서 입력받은 데이터를 MariaDB에 저장시키기 with Docker (0) | 2024.09.19 |
| 데이터엔지니어 부트캠프 - nGrinder로 Nginx 로드밸런서 분산 처리 테스트해보기 (with Docker) (9주차) (1) | 2024.09.06 |
| 데이터엔지니어 부트캠프 - FastAPI로 만든 API 서비스를 Docker 이미지로 빌드하기 그리고 Fly.io로 배포하기 (8주차) (1) | 2024.09.01 |
| 데이터엔지니어 부트캠프 - 두번째 팀프로젝트 (8/26~8/28) (8주차) (12) | 2024.09.01 |



