

imhamburger 님의 블로그
아파치 스파크 - 정형화 API 이해하기 본문
RDD
- 의존성
- 파티션
- 연산 함수: Partition => Iterator[T]
어떤 입력을 필요로 하고 현재의 RDD가 어떻게 만들어지는지 스파크에게 가르쳐 주는 의존성이 필요하다.
결과를 새로 만들어야 하는 경우에 스파크는 이 의존성 정보를 참고하고 연산을 다시 반복해서 RDD를 다시 만들 수 있다.
파티션은 스파크에게 작업을 나눠서 이그제큐터들에 분산해 파티션별로 병렬 연산할 수 있는 능력을 부여한다.
스파크는 지역성 정보를 사용하여 각 이그제큐터가 가까이 있는 데이터를 처리할 수 있는 이그제큐터에게 우선적으로 작업을 보낼 것이다.
RDD는 RDD에 저장되는 데이터를 Iterator[T] 형태로 만들어 주는 연산 함수를 갖고 있다.
-> 이 모델에는 문제가 있다.
연산 함수나 연산식 자체가 스파크에 투명하지 않았다.
스파크가 연산 함수 안에서 무얼 하는지 알 수 없었다.
따라서 스파크 구조 확립을 위한 핵심 개념들을 도입했다.
필터링, 선택, 집합연산, 집계, 평균, 그룹화 같은 고수준 연산으로 표현되었다.
dataRDD = sc.parallelize([("Broke", 20), ("Denny", 31), ("Jules", 30),
("TD", 35), ("Broke", 25)])
agesRDD = (dataRDD
.map(lambda x: (x[0], (x[1], 1)))
.reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))
.map(lambda x: (x[0], x[1][0]/x[1][1])))
스파크에게 어떻게 키를 집계하고 평균 계산을 하는지 람다 함수로 알려주는 이 코드는 이해하기에 복잡하고 어렵다.
반면, 고수준 DSL 연산자들과 데이터 프레임 API를 써서 스파크에게 무엇을 할지 알려준다면?
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg
spark = (SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate())
data_df = spark.createDataFrame([("Broke", 20), ("Denny", 31),("Jules", 30),
("TD", 35), ("Brooke", 25)], ["name", "age"])
avg_df = data_df.groupBy("name").agg(avg("age"))
avg_df.show()
더 명료하고 이해하기 쉬운 쿼리를 작성할 수 있다!
스칼라 코드로도 표현할 수 있다.
import org.apache.spark.sql.functions.avg
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("AuthorsAges")
.getOrCreate()
val dataDF = spark.createOrDataFrame(Seq(("Brooke",20), ("Brooke", 25), ("Denny",31),
("Jules", 30), ("TD", 35))).toDF("name", "age")
val avgDF = dataDF.groupBy("name").agg(avg("age"))
avgDF.show()
데이터프레임 API
데이터 타입에는 정수, 문자열, 배열, 맵, 실수, 날짜, 타임스탬프 등 이 있다.
칼럼 이름이 String, Byte, Long, Map 등의 타입 중 하나가 되도록 선언하거나 정의할 수 있다.
기본적인 데이터 타입
스칼라 데이터 타입
| 데이터 타입 | 스칼라에서 할당되는 값 | 초기생성 API |
| ByteType | Byte | DataTypes.ByteType |
| ShortType | Short | DataTypes.ShortType |
| IntegerType | Integer | DataTypes.IntegerType |
| LongType | Long | DataTypes.LongType |
| FloatType | Float | DataTypes.FloatType |
| DoubleType | Double | DataTypes.DoubleType |
| BooleanType | Boolean | DataTypes.BooleanType |
| DecimalType | java.math.BigDecimal | DecimalType |
파이썬 데이터 타입
| 데이터 타입 | 파이썬에서 할당되는 값 | 초기생성 API |
| ByteType | int | DataTypes.ByteType |
| ShortType | int | DataTypes.ShortType |
| IntegerType | int | DataTypes.IntegerType |
| LongType | int | DataTypes.LongType |
| FloatType | float | DataTypes.FloatType |
| DoubleType | float | DataTypes.DoubleType |
| StringType | str | DataTypes.StringType |
| BooleanType | bool | DataTypes.BooleanType |
| DecimalType | decimal.Decimal | DecimalType |
스파크의 정형화 타입과 복합 타입
정형화 타입에는 BinaryType, TimestampType, DateType, ArrayType, MapType, StructType, StructField 타입이 있다.
스키마와 데이터 프레임 만들기
스파크에서 스키마는 데이터 프레임을 위해 칼럼 이름과 연관된 데이터 타입을 정의한 것이다.
미리 스키마를 정의하는 것은 여러가지 장점이 있다.
- 스파크가 데이터 타입을 추측해야 하는 책임을 덜어준다.
- 스파크가 스키마를 확정하기 위해 파일의 많은 부분을 읽어 들이려고 별도의 잡을 만드는 것을 방지한다. 데이터 파일이 큰 경우, 비용과 시간이 많이 드는 작업이다.
- 데이터가 스키마와 맞지 않는 경우, 조기에 문제를 발견할 수 있다.
스키마 타입 정의 2가지
from pyspark.sql.types import (
StructType, StructField,
StringType, IntegerType, LongType,
DoubleType, BooleanType, TimestampType
)
schema = StructType([
StructField("user_id", LongType(), nullable=False),
StructField("user_name", StringType(), nullable=True),
StructField("age", IntegerType(), nullable=True),
StructField("is_active", BooleanType(), nullable=False),
StructField("signup_at", TimestampType(), nullable=True),
StructField("purchase_amount", DoubleType(), nullable=True),
])
df = spark.createDataFrame(data=[], schema=schema)
df.printSchema()
DDL문 이용
schema_ddl = """
user_id BIGINT,
user_name STRING,
age INT,
is_active BOOLEAN,
signup_at TIMESTAMP,
purchase_amount DOUBLE
"""
df = spark.createDataFrame(data=[], schema=schema_ddl)
df.printSchema()
#정의했던 스키마로 데이터 프레임 생성
blogs_df = spark.createDataFrame(data, schema)
직접 데이터를 입력하지 않고 JSON 파일에서 데이터를 읽어 들인다고 해도 스키마 정의는 동일할 것이다.
JSON 파일에서 읽어 들이는 스칼라 예제
val schema = StructType(Array(StructField("id", IntegerType, false),~
#JSON 파일 경로를 읽는다.
val jsonFile = args(0)
#JSON 파일을 읽어 미리 정의한 스키마로 데이터 프레임을 생성한다.
val blogsDF = spark.read.schema(schema).json(jsonFile)
칼럼과 표현식
사용자는 이름으로 칼럼들을 나열해 볼 수 있고, 관계형 표현이나 계산식 형태의 표현식으로 그 값들에 연산을 수행할 수 있다.
blogsDF.select(expr("Hits * 2")).show(2)
blogsDF.select(col("Hits") * 2).show(2)
# 세 칼럼을 연결하여 새로운 칼럼을 만들고 그 칼럼을 보여준다.
blogsDF
.withColumn("AuthorsId", (concat(expr("First"), expr("Last"), expr("Id"))))
.select(col("AuthorsId"))
.show(4)
# 이 문장들은 모두 동일한 결과를 보여주며 표현만 약간씩 다르다.
blogsDF.select(expr("Hits")).show(2)
blogsDF.select(col("Hits")).show(2)
blogsDF.select("Hits").show(2)
로우
스칼라 예제
import org.apache.spark.sql.Row
# Row 객체 생성
val blogRow = Row(6, "Reynold", "Xin", "https://~~", 252432, "3/2/2015",
Array("twitter", "LinkedIn"))
# 인덱스로 개별 아이템에 접근한다.
blogRow(1)
res62: Any = Reynold
파이썬 예제
from pyspark.sql import Row
blog_row = Row(6, "Reynold", "Xin", "https://~~", 252432, "3/2/2015",
Array("twitter", "LinkedIn"))
# 인덱스로 개별 아이템에 접근한다.
blog_row[1]
'Reynold'
자주 쓰이는 데이터 프레임 작업들
데이터 프레임에서 일반적인 데이터 작업을 수행하려면 우선 구조화된 데이터를 갖고 있는 데이터 소스에서 데이터 프레임으로 로드를 해야한다.
스파크는 이를 위해 DataFrameReader라는 이름의 인터페이스를 제공하며 이는 JSON, CSV, Parquet, 텍스트, 에이브로, ORC 같은 다양한 포맷의 데이터 소스에서 데이터를 읽어 데이터 프레임으로 갖고 오게 해준다.
동일하게 특정 포맷의 데이터 소스에 데이터 프레임의 데이터를 써서 내보내기 위해서는 DataFrameWriter를 쓴다.
spark.read.csv() 함수는 CSV 파일을 읽어서 row 객체와 스키마에 맞는 타입의 이름 있는 칼럼들로 이루어진 데이터 프레임을 되돌려 준다.
데이터 프레임을 파케이 파일이나 SQL 테이블로 저장하기
#파이썬에서 파케이로 저장
parquet_path = ...
fireDF.write.format("parquet").save(parquet_path)
#테이블로 저장
parquet_table = ...# 테이블 이름
fire_df.write.format("parquet").saveAsTable(parquet_table)
트랜스포메이션과 액션
1. 프로젝션과 필터
프로젝션은 관계형 DB 식으로 말하면 필터를 이용해 특정 관계 상태와 매치되는 행들만 되돌려 주는 방법이다.
스파크에서 select() 메서드로 수행하는 반면, 필터는 filter()나 where() 메서드로 표현된다.
few_fire_df = (fire_df
.select("IncidentNumber", "AvailableDtTm", "CallType")
.where(col("CallType") != "Medical Incident"))
few_fire_df.show(5, truncate=False)
이 밖에도 countDistinct(), isNotNull(), distinct() 필터링을 할 수 있다.
2. 칼럼의 이름 변경 및 추가 삭제
간혹 스타일이나 컨벤션 준수의 이유로, 혹은 가독성이나 간결성을 위해 특정 칼럼의 이름을 바꿔야할 때가 있다.
new_fire_df = fire_df.withColumnRenamed("Delay", "ResponseDelayedinMins")
(new_fire_df
.select("ResponseDelayedinMins")
.where(col("ResponseDelayedinMins") > 5)
.show(5,False))
데이터 프레임 변형은 변경 불가 방식으로 동작하므로 withColumnRenamed()로 컬럼 이름을 변경할 때는 , 기존 칼럼 이름을 갖고 있는 원본을 유지한 채로 컬럼 이름이 변경된 새로운 데이터 프레임을 받아 오게 된다.
문자열로 된 날짜를 날짜타입으로 바꾸려면?
fire_ts_df = (new_fire_df
.withColumn("IncidentDate", to_timestamp(col("CallDate"), MM/dd/yyyy"))
.drop("CallDate")
#변환된 컬럼들을 가져온다.
(fire_ts_df
.select("IncidentDate")
.show(5, False))
수정된 날짜/시간 컬럼을 가지게 되었으므로 이후에 데이터를 탐색을 할 때는 spark.sql.functions에서 dayofmonth(), dayofyear(), dayofweek() 같은 함수들을 써서 질의할 수 있다.
3. 집계연산
groupBy(), orderBy(), count()와 같이 데이터 프레임에서 쓰는 일부 트랜스포메이션과 액션은 칼럼 이름으로 집계해서 각각 개수를 세어주는 기능을 제공한다.
데이터프레임 API는 collect() 함수를 제공하지만 극단적으로 큰 데이터 프레임에서는 메모리 부족 예외를 발생시킬 수 있기때문에 자원도 많이 쓰고 위험하다.
드라이버에 결과 숫자 하나만 전달하는 count()와는 달리 collect()는 전체 데이터 프레임 혹은 데이터 세트의 모든 Row 객체 모음을 되돌려 준다. 몇개의 Row 결과만 보고 싶다면 최초 n개의 Row 객체만 되돌려 주는 take(n) 함수를 쓰는 것이 훨씬 나을 것이다.
4. 그 외
min(), max(), sum(), avg() 등을 제공한다.
조금 더 데이터 사이언스에서 쓰이는 고수준 요구사항을 만족하려면 stat(), describe(), correlation(), covariance() 등의 API 문서를 읽어보면 된다!
데이터세트 API
Spark SQL 이후(2.x~) 기준에서 DataFrame과 Dataset은 같은 추상화 계층에 있고, 차이는 타입 안정성과 언어 지원에 있다는 점이다.
데이터 세트는 정적 타입 API와 동적 타입 API의 두 특성을 모두 가진다.

정적 타입 객체, 동적 타입 객체, 포괄적인 Row
스파크가 지원하는 언어들에서 데이터세트는 자바와 스칼라에서 통용되며, 반대로 파이썬과 R에서는 데이터 프레임만 사용 가능하다.
이는 파이썬과 R이 컴파일 시 타입의 안전을 보장하는 언어가 아니기 때문이다.
데이터세트 생성
데이터세트를 만들 때에도 해당 스키마를 알아야 한다. JSON이나 CSV라면 스키마 추론이 가능하겠지만 대용량 데이터에서는 이런 작업은 품이 많이 든다.
스칼라에서 데이터세트를 만들 때 결과 데이터세트가 쓸 스키마를 지정하는 가장 쉬운 방법은 스칼라의 케이스 클래스를 사용하는 것이다. 자바라면 자바빈 클래스를 쓸 수 있다.
스칼라 케이스
case class DeviceIoTData (battery_level: Long, c02_level:Long,
device_name: String)
데이터세트에서 가능한 작업들
데이터 프레임에서 트랜스포메이션이나 액션들을 수행했던 것처럼, 데이터세트에서도 가능하다.
val filterTempDS = ds.filter(d => d.temp > 30 && d.humidity > 70)
filterTempDS: org.apache.spark.sql.Dataset[DeviceIoTData] = [battery_level...]
filterTempDS.show(5, false)
filter(), map(), groupBy(), select(), take() 등등
스파크 SQL과 하부의 엔진
- 스파크 컴포넌트들을 통합하고 정형화 데이터 관련 작업을 단순화할 수 있도록 추상화한다.
- 아파치 하이브 메타스토어와 테이블에 접근한다.
- 정형화된 파일 포맷(json, csv, 텍스트, 파케이 등) 에서 스키마와 정형화 데이터를 읽고 쓰며 데이터를 임시 테이블로 변환한다.
- 빠른 데이터 탐색을 할 수 있도록 대화형 스파크 SQL 셸을 제공한다.
- 표준 데이터베이스 jdbc/odbc 커넥터를 통해 외부의 도구들과 연결할 수 있는 중간 역할을 한다.
- 최종 실행을 위해 최적화된 질의 계획과 jvm을 위한 최적화된 코드를 생성한다.
스파크 sql 엔진의 핵심에는 카탈리스트 옵티마이저와 텅스텐 프로젝트가 있다.
이들은 함께 상위수준의 데이터 프레임과 데이터세트 api 및 sql 쿼리 등을 지원한다.
카탈리스트 옵티마이저
카탈리스트 옵티마이저는 연산 쿼리를 받아 실행 계획으로 변환한다.
다음과 같은 변환 과정을 거친다.
분석 -> 논리적 최적화 -> 물리 계획 수립 -> 코드 생성
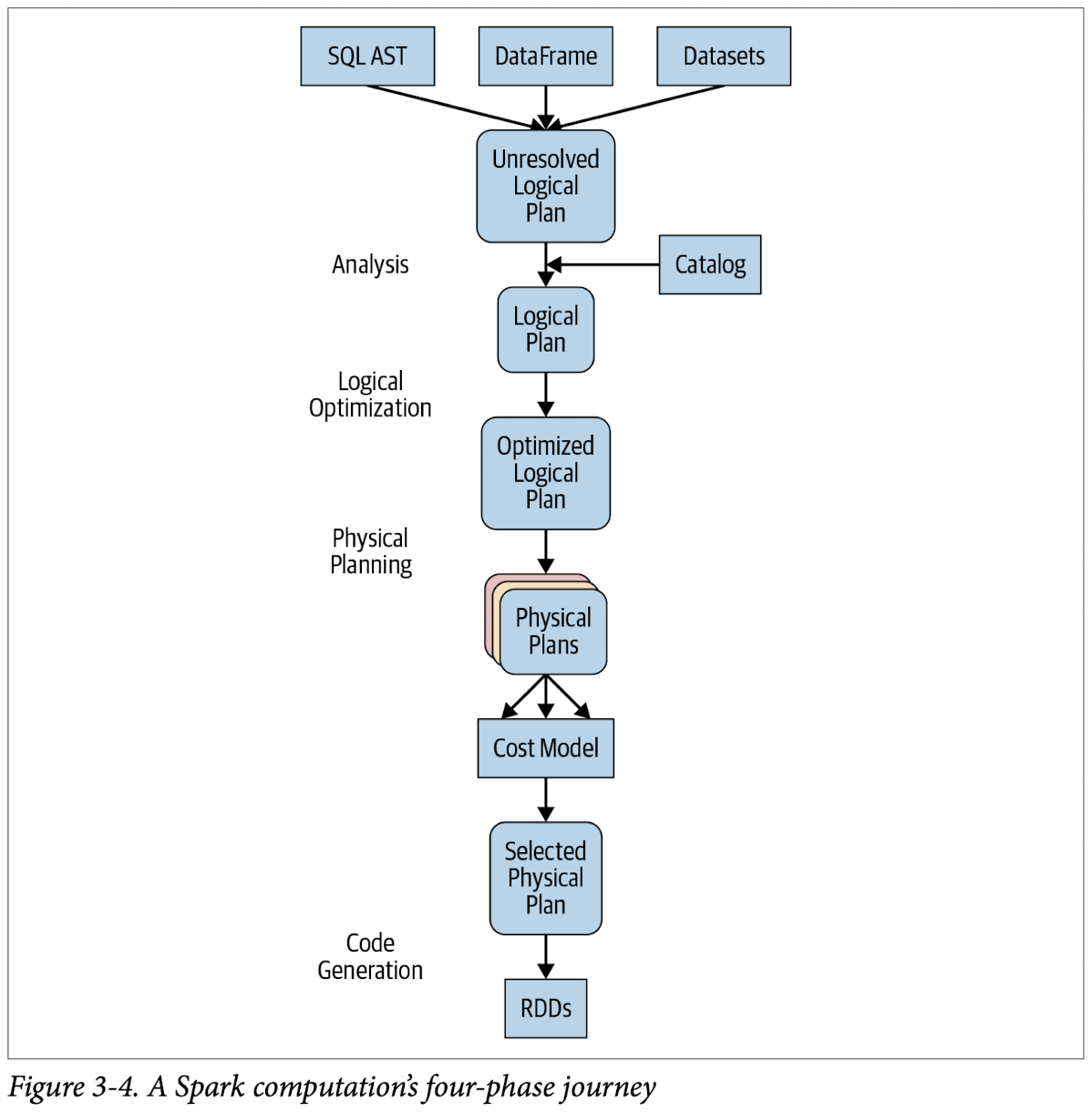
파이썬 코드가 거치게 되는 다른 스테이지들을 보려면 데이터 프레임에서 count_mnm_df_explain(True) 함수를 실행하면 된다.
스칼라에서는 df.queryExecution.logical 이나 df.queryExecution.optimizedPlan 을 실행하면 된다.

1단계: 분석
스파크 sql 엔진은 sql이나 데이터 프레임 쿼리를 위한 추상 문법 트리(abstract syntax tree, AST) 생성으로 시작한다.
초기 단계에서는 어떤 컬럼이나 테이블 이름이든 칼럼, 데이터 타입, 함수, 테이블, 데이터베이스 이름 목록을 갖고 있는 스파크 sql 의 프로그래밍 인터페이스인 catalog 객체로 접근하여 가져올 수 있다.
2단계: 논리적 최적화
표준적인 규칙을 기반으로 하는 최적화 접근 방식을 적용하면서 카탈리스트 옵티마이저는 먼저 여러 계획들을 수립한 다음 비용 기반 옵티마이저(cost based optimizer, CBO)를 써서 각 계획에 비용을 책정한다.
이 계획들은 연산 트리로 배열된다. 예를 들면 트리들은 조건절 하부 배치, 칼럼 걸러내기, boolean 연산 단순화 등을 포함한다.
이 논리 계획은 물리 계획 수립의 입력 데이터가 된다.
3단계: 물리 계획 수립
스파크 sql은 스파크 실행 엔진에서 선택된 노리 계획을 바탕으로 대응되는 물리적 연산자를 사용해 최적화된 물리 계획을 생성한다.
4단계: 코드 생성
스파크는 컴파일러처럼 동작한다. 포괄 코드 생성을 가능하게 하는 프로젝트 텅스텐이 여기서 역할을 하게 된다.
포괄 코드 생성이란 물리적 쿼리 최적화 단계로 전체 쿼리를 하나의 함수로 합치면서 가상 함수 호출이나 중간 데이터를 위한 CPU 레지스터 사용을 없애버린다.
'스파크(Spark)' 카테고리의 다른 글
| 스파크 애플리케이션 개념의 이해 (0) | 2026.01.21 |
|---|---|
| 스파크(Spark) - 제플린으로 만든 그래프에 select box 구현하기 (0) | 2024.08.21 |
| 스파크(Spark) - JSON파일을 읽어와 아파치스파크에서 파싱하기 (0) | 2024.08.20 |
| 스파크(Spark) - 분산 처리 시스템 구조 이해하기 (1) | 2024.08.14 |
| Apache Zeppelin process died 오류, Zeppelin 포트번호 변경하기 (0) | 2024.08.09 |


