

imhamburger 님의 블로그
스파크(Spark) - 분산 처리 시스템 구조 이해하기 본문
지난글에서 스파크가 뭔지?에 대해 설명하였다. 스파크는 빅데이터 처리를 위한 오픈 소스 분산 처리 시스템이다.
그리고 분산 처리를 하기위해 스파크에서 중요한 역할을 하는 두 가지 핵심 컴포넌트가 있다. 컴포넌트 의 의미는 각각 독립된 모듈이라고 생각하면 된다.
두 가지 핵심 컴포넌트를 설명하기 전에 알아야할 개념이 있다.
바로 '클러스터' 이다.
클러스터는 여러 대의 컴퓨터(노드)가 서로 연결되어 협력하여 작업을 수행하는 시스템을 말한다.
이는 빅데이터 처리를 위해 여러 노드가 병렬로 작업을 수행하며, 각 노드는 독립적인 컴퓨터로서 네트워크를 통해 상호작용한다.
그러니까, 카페에서 커피 100잔을 만들 때 어떤 사람은 아메리카노, 어떤 사람은 카푸치노, 어떤 사람은 카페 라떼 등.. 나누어 만들지만 어쨋든 주문된 100잔을 완성한다. 이 100잔을 만드는 모든 사람을 일컬어 클러스터라고 보면 된다.
클러스터를 이해했다면 이제 핵심 컴포넌트에 대해 알아보자.
1. Master (마스터)
- 마스터는 클러스터의 중앙 제어 장치로, 작업을 스케줄링하고 Worker 노드에 작업을 분배하는 역할이다. (==에어플로우의 Dag)
- 마스터는 사용자(나)로부터 실행할 작업을 받아 여러 Task로 분할한다. 이를 모니터링하고 실패한 작업을 다시 실행하도록 조정한다.
- 일반적으로 클러스터에서 하나의 마스터만 존재하며 고가용성을 위해 여러 개의 Standby Master 노드를 구성할 수 있다.
여기서 고가용성의 의미는 항상 사용할 수 있다는 면에서 고가용성이라고 하는 것이다.
2. Worker (워커)
- 워커는 실제로 데이터를 처리하고 계산 작업을 수행하는 노드이다.(==에어플로우의 Operator)
- 마스터로부터 받은 Task를 실행하고 데이터 처리 결과를 마스터에게 보고한다.
- 각 워커는 1개 이상의 Executor 프로세스를 실행하며, 이 Executor가 Task를 수행하고 메모리 및 디스크를 관리한다.
- 클러스터에는 여러 워커가 있을 수 있으며 할당받은 작업을 병렬로 처리한다.
- 워커는 로컬 리소스(CPU, 메모리)를 사용하여 작업을 수행한다.
스파크의 핵심 컴포넌트는 이렇고.. 사실은 스파크가 분산 처리를 하는데 더 복잡한 구조를 가지고 있다.
우선 아래 그림을 살펴보자.


마스터는 앞에서 언급했다시피 중앙 제어 장치로 스케줄링, 작업할당 담당
- Spark Context: 내가 만든 데이터를 불러오고 가공하고 내보내는 기능. 지난글에서 spark.sql로 작업하였던 것들
- Driver Process: 내가 만든 애플리케이션(기능)을 실행하는 메인 프로세스로 코드를 실행하고 작업을 생성하여 클러스터매니저에게 제출, 또한 작업의 상태를 모니터링하고 결과를 수집한다.

클러스터 매니저는 전체 클러스터의 리소스(CPU, 메모리)를 관리하는 컴포넌트
- YARN, Mesos, Spark 자체 내장 클러스터 매니저를 사용할 수 있다.
- 드라이버가 요청한 작업에 필요한 자원을 할당하고, 작업을 실행할 워커 노드를 관리.
- 말 그대로 매니저!
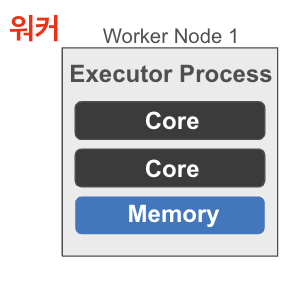
워커는 실제로 데이터를 처리하고 계산 작업을 수행하는 노드
- 각 워커는 마스터로부터 할당된 작업 실행
- Core와 Memory는 클러스터매니저한테 할당받는다.
- Executor Process: Worker 노드에서 작업을 실행하는 프로세스
- 실행 결과를 메모리에 저장하거나 필요 시 디스크에 기록

그럼 저 HDFS는 뭐지?
HDFS(Hadoop Distributed File System)는 Apache Hadoop의 핵심 구성 요소 중 하나로, 빅데이터를 저장하고 관리하는 분산 파일 시스템이다.
- 워커노드가 여러대 있는데 공용으로 사용해야할 파일 시스템이 필요하기 때문에 존재
- 따라서, 분산되어진 데이터들을 한꺼번에 로드시켜서 사용할 수 있다.(데이터접근 속도 최적화)
- 뿐만 아니라, 손상된 워커노드가 있다면 이를 인식하고 데이터가 손실되지 않도록 장애 복구 기능을 제공한다. (장애 복구)
- 노드 간의 복제 및 다중 복제본 저장을 통해 노드 장애 시에도 데이터 접근성을 유지한다.(고가용성)
노드가 어떤식으로 장애가 날 수 있지?
> 데이터 양이 할당받은 CPU 혹은 메모리를 넘어서서 터질 경우랄까?
HDFS가 장애 복구를 어떻게 작동하는지는 복잡하지만, 간단하게 설명하자면 HDFS에는 네임노드라는 중앙 메타데이터 서버가 있는데 파일 시스템의 구조(파일 이름, 디렉토리, 블록 위치 등)와 각 블록의 복제본 위치를 관리한다.
만약 데이터 블록이 손상되었거나 체크섬 검증에 실패한 경우,
네임노드는 이 블록을 손상된 것으로 인식하고, 다른 복제본을 사용하여 새로운 복제본을 생성한다.
이렇게 해서 손상된 블록을 복구하고 데이터를 안전하게 유지한다.
Spark Standalone Mode - 스파크 클러스터 사용법 (공식문서)
1. standalone master 서버 실행
$ cd /spark-3.5.1-bin-hadoop3
$ ./sbin/start-master.sh #start-master 실행- http://localhost:8080 에서 확인
2. worker 실행
$ ./sbin/start-worker.sh <master-spark-URL>- <master-spark-URL>은 master 실행 후 http://localhost:8080 에서 확인
- worker 서버는 http://localhost:8081
3. configuration 옵션 설정하여 실행
#master
$ ./sbin/start-master.sh -h {IP주소} --webui-port {포트번호}
#worker
$ ./sbin/start-worker.sh {master-URL} -c 4 -m 3G #c는 코어 m은 메모리를 의미- 맥에서 IP주소 확인은?
$ ifconfig | grep inet
--num-executor 는 Spark Standalone Mode 에서는 작동하지 않는다.
--total-executor-core는 전체 cluster의 executor의 코어 개수를 의미한다.
'스파크(Spark)' 카테고리의 다른 글
| 아파치 스파크 - 정형화 API 이해하기 (0) | 2026.01.31 |
|---|---|
| 스파크 애플리케이션 개념의 이해 (0) | 2026.01.21 |
| 스파크(Spark) - 제플린으로 만든 그래프에 select box 구현하기 (0) | 2024.08.21 |
| 스파크(Spark) - JSON파일을 읽어와 아파치스파크에서 파싱하기 (0) | 2024.08.20 |
| Apache Zeppelin process died 오류, Zeppelin 포트번호 변경하기 (0) | 2024.08.09 |


