
imhamburger 님의 블로그
데이터엔지니어 부트캠프 - 세번째 팀프로젝트 (10/5 & 10/7~10/8) (14주차) 본문
다시 팀프로젝트 기간이 돌아왔다.
이번에도 3일간 과제를 수행하면 된다!
팀구성은 5인 1조인데 우리의 팀 이름은 "3Kcal" 으로 정했다.
딱히 팀 이름에 그럴싸한 아이디어가 떠오르지 않아...약간 막지은 느낌이 있다..ㅋ
팀프로젝트 주제
- 임의의 ML 및 DL 모델에 대한 서비스를 관리 제어 하는 내부 관리 프로그램
- streamlit 을 통해 관리 화면을 html css js 없이 python 만으로 생성
- 관리화면은 예측 결과에 대한 검토 및 잘못된 예측에 대한 코맨트, 라벨 기록 가능
- 그 외 관리 화면에서 위 검토된 코맨트, 라벨을 기반으로 서비스 예측 정확성 통계 도출
모델 선정
우리가 선택한 ML은 글을 읽어 감정을 예측하는 모델이다. (여기)
이 모델을 선택한 이유는... 개인적인 생각으로는!
이전에 회사에서 마케팅부서였었는데 고객들의 리뷰를 관리를 해야했다. (CRM)
그런데 그러한 리뷰를 관리하기 위해서는 수작업으로 해야했고 시간이 꽤나 걸리는 작업이었다.
그렇지만 이 모델이 정말 예측이 잘된다면?! 5시간 걸릴 것을 30분 내로 끝낼 수 있기 때문에 매우 유용한 모델이라 생각했다.
따라서, 나는 이 모델을 선택하였다.
(그렇지만, 이 프로젝트 목적은 모델이 얼마나 예측을 잘 하는지?를 평가하기 위함이다.!!)
우리가 사용한 기술
1. Python
2. Pyspark
3. Apache Airflow
4. Streamlit
5. Mariadb
6. FastAPI
아키텍쳐 설계
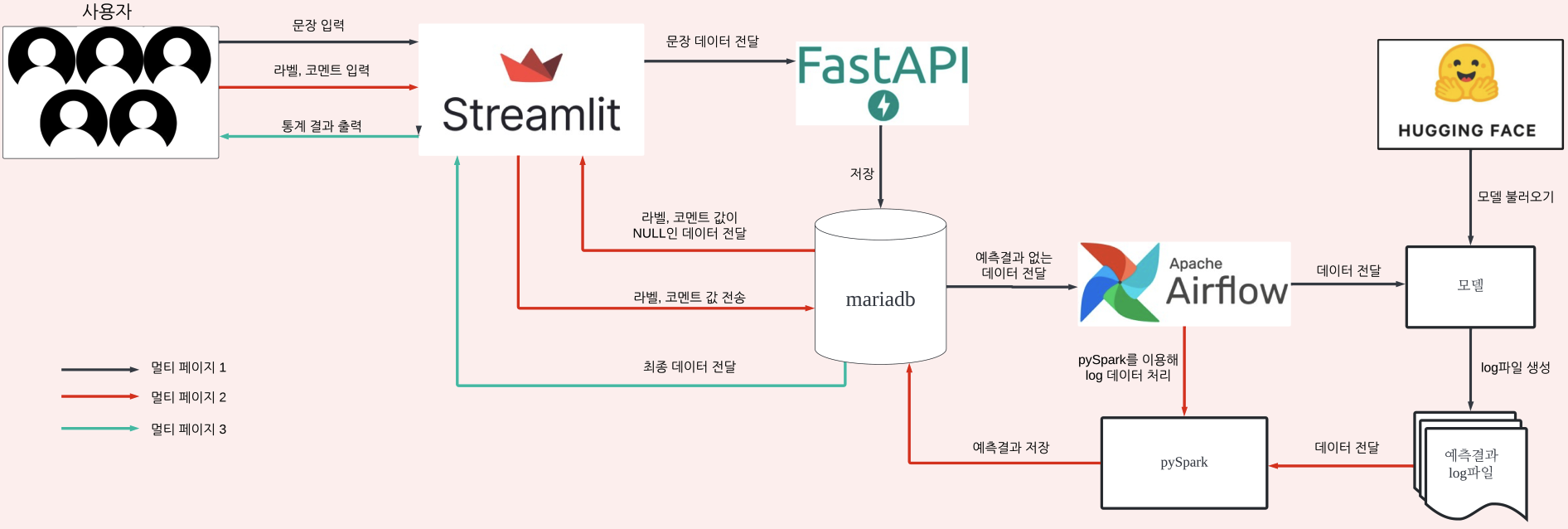
설명을 덧붙이자면...
- 사용자 입력값 수집 및 MariaDB 저장
- FastAPI를 사용해 Streamlit에서 사용자가 입력한 값을 API로 받아 MariaDB에 저장하는 백엔드를 구현한다.
- 프론트엔드 구현
- Streamlit을 이용해 프론트엔드 화면을 구현한다. 사용자가 값을 입력하고 제출할 수 있는 UI를 만들고, 이 데이터를 Pymysql을 이용해 MariaDB에 저장한다.
- MariaDB 설정 및 테이블 구축
- MariaDB 데이터베이스를 설정하고, 저장할 데이터를 위한 테이블을 구축한다.
- Airflow를 사용한 예측 모델 적용
- Airflow를 사용해 MariaDB에서 데이터를 읽어오고, 이를 바탕으로 예측 모델을 적용한다.
- 예측 결과와 작업 로그를 log 파일로 생성한다. (log 파일은 3분마다 저장)
- PySpark로 데이터 정리 및 자동화
- log 파일과 MariaDB 데이터를 PySpark로 처리하여 정리한다. (join)
- Airflow 스케줄러를 사용해 주기적으로 PySpark 작업을 실행하고, 결과를 다시 MariaDB의 특정 컬럼에 저장한다.
(추가 단계)
- Streamlit을 이용해 사용자가 예측된 결과와 비교할 수 있도록 '정답 값'을 입력하는 화면을 제공한다. (페이지 2)
- 사용자가 입력한 정답 값을 Pymysql을 이용해 MariaDB의 특정 컬럼에 저장한다.
6. 데이터 시각화
- 최종적으로 MariaDB에서 데이터를 읽어와 Streamlit과 Pandas를 사용해 그래프로 시각화하여 결과를 보여준다.
이 추가된 단계에서는 사용자가 예측 모델의 결과와 비교할 '정답' 데이터를 입력할 수 있는 기능을 제공하고, 이를 데이터베이스에 저장해 기존의 ML이 얼마나 정확하게 예측하는지를 분석하고 시각화에 활용할 수 있게 한다.
그리고 FastAPI 기능, Streamlit, Mariadb 는 Docker 이미지로 만들어 실행시킬 것이며, Airflow는 로컬에서 실행시킬 것이다.
Airflow를 로컬로 실행시키는 이유는 model 파일을 읽고 처리하는 것이 너무 무거워 우리가 가지고 있는 AWS 인스턴스로는 부족하기 때문이다.
나의 Task
나는 여기에서 다음과 같은 업무를 맡았다.
1. 사용자 입력값 수집 및 MariaDB 저장
2. MariaDB 설정 및 테이블 구축
3. PySpark로 데이터 정리
4. (추가 단계)
나의 에러 리포트
에러 1) Docker를 run하는 과정에서 에러
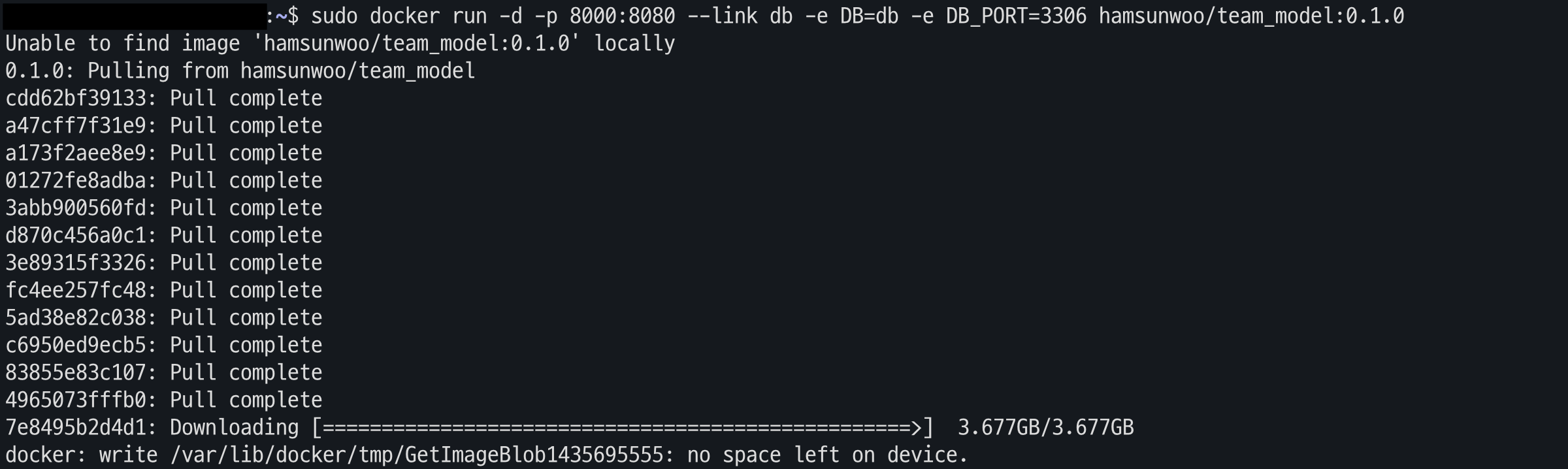
발생이유
AWS 공간 부족으로 인한........
해결 방법
처음에 프로세스를 잘못 이해하여 FastAPI 기능에 모델까지 적용하는 것을 구현했어서 파일 크기가 8GB 였다.
FastAPI에는 모델 적용하는 것이 필요없어 관련 dependencies를 삭제하고 build 하여 크기(-7GB)를 줄였고 해당 에러를 해결할 수 있었다.
에러 2) PySparkValueError
Traceback (most recent call last):
File "/Users/seon-u/code/pyspark/src/pyspark/main.py", line 48, in <module>
join()
File "/Users/seon-u/code/pyspark/src/pyspark/main.py", line 28, in join
df = spark.createDataFrame(pdf)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/seon-u/code/pyspark/.venv/lib/python3.11/site-packages/pyspark/sql/session.py", line 1440, in createDataFrame
return super(SparkSession, self).createDataFrame( # type: ignore[call-overload]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/seon-u/code/pyspark/.venv/lib/python3.11/site-packages/pyspark/sql/pandas/conversion.py", line 363, in createDataFrame
return self._create_dataframe(converted_data, schema, samplingRatio, verifySchema)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/seon-u/code/pyspark/.venv/lib/python3.11/site-packages/pyspark/sql/session.py", line 1485, in _create_dataframe
rdd, struct = self._createFromLocal(map(prepare, data), schema)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/seon-u/code/pyspark/.venv/lib/python3.11/site-packages/pyspark/sql/session.py", line 1093, in _createFromLocal
struct = self._inferSchemaFromList(data, names=schema)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/seon-u/code/pyspark/.venv/lib/python3.11/site-packages/pyspark/sql/session.py", line 969, in _inferSchemaFromList
raise PySparkValueError(
pyspark.errors.exceptions.base.PySparkValueError: [CANNOT_DETERMINE_TYPE] Some of types cannot be determined after inferring.
발생이유
해당 에러는 PySpark에서 pandas.DataFrame을 Spark DataFrame으로 변환할 때, 일부 데이터의 타입을 자동으로 추론할 수 없어서 발생하는 문제였다. 에러 메시지의 주요 원인은 pandas.DataFrame의 일부 열에 대해 Spark가 적절한 데이터 타입을 인식하지 못하는 경우이다.
해결 방법
다음과 같이 데이터 타입을 직접적으로 명시해주니 해결할 수 있었다.
from pyspark.sql.types import StructType, StringType, FloatType, TimestampType, IntegerType, StructField
# 스키마 정의
schema = StructType([
StructField("num", IntegerType(), True),
StructField("comments", StringType(), True),
StructField("request_time", StringType(), True),
StructField("request_user", StringType(), True)
])
spark_df = spark.createDataFrame(df, schema=schema)
에러 3) streamlit.errors.StreamlitDuplicateElementKey
raise StreamlitDuplicateElementKey(user_key)
streamlit.errors.StreamlitDuplicateElementKey: There are multiple elements with the same key='select_request_user'. To fix this, please make sure that the key argument is unique for each element you create.
발생이유
StreamlitDuplicateElementKey 오류가 발생하는 이유는 동일한 key 값이 여러 곳에서 사용되었기 때문이다. 특히, selectbox와 같은 UI 요소에 동일한 key 값이 중복되면 이 오류가 발생한다.
이 문제를 해결하기 위해서는 각 UI 요소에 고유한 key 값을 지정해야 한다. key 값은 고유해야 하며, 특히 같은 요소가 여러 번 생성될 때는 각각 고유한 key를 부여해야 한다.
해결 방법
st.selectbox를 사용하는 코드마다 각각의 고유한 key를 지정해주었다. key= ~~
user_unique_id = "user_select_1"
num_unique_id = "num_select_1"
num_option = st.selectbox(
"num 선택",
options,
index=0,
placeholder="num을 선택해주세요.",
key=f"select_num_{unique_id}" # 고유한 key 값 설정
)
user = st.selectbox(
"request user 선택",
options,
index=0, # 기본값은 "모든 사용자"
placeholder="request_user를 선택해주세요.",
key=f"select_request_user_{unique_id}" # 고유한 key 값 설정
)
새롭게 알게된 지식
우리팀의 프로세스는 에어플로우 dag가 총 2개 실행된다.
dag1: Airflow를 사용해 MariaDB에서 데이터를 읽어오고, 이를 바탕으로 예측 모델을 적용
dag2: 예측 결과와 작업 로그를 log 파일로 생성한다. (log 파일은 3분마다 저장)
dag1이 먼저 완성된 후 dag2를 실행시켜야 하는데, 처음에는 시간단위를 달리주어 하려고 하였지만 그건 너무 Risk가 컸다.
이유는 한 dag가 갑자기 중단될 시 다른 건 계속 돌아갈 수도 있기 때문에 데이터가 꼬이기 때문이다.
알아본 결과,
Airflow의 ExternalTaskSensor를 사용하면 됐다!
Airflow의 ExternalTaskSensor를 사용하여 다른 DAG의 특정 작업이 완료될 때까지 대기하는 작업을 정의하고, 이를 통해 DAG 간의 의존성을 설정할 수 있다.
dag
from datetime import datetime, timedelta
import sys
import os
import pandas as pd
from airflow import DAG
import subprocess
from airflow.models import Variable
from airflow.sensors.external_task import ExternalTaskSensor
from airflow.operators.bash import BashOperator
from airflow.operators.empty import EmptyOperator
os.environ['LC_ALL'] = 'C'
with DAG(
'save_db',
default_args={
'depends_on_past': False,
'retries': 1,
'retry_delay': timedelta(seconds=3),
},
max_active_runs=1,
max_active_tasks=3,
description='save_db',
schedule='*/3 * * * *',
start_date=datetime(2024, 10, 4),
end_date=datetime(2024,10,8),
catchup=True,
tags=['predict', 'ml', 'db'],
) as dag:
# Model Dag의 predict task를 실행할 때 까지 대기 시키는 센서오퍼레이터
wait_logf = ExternalTaskSensor(
task_id='wait_logf',
external_dag_id='predict_emotion', # DAG A의 ID
external_task_id='prediction', # DAG A의 마지막 태스크 ID (필요한 경우)
allowed_states=['success'],
failed_states=['failed', 'skipped'],
timeout=300, # 5분 내에 완료되지 않으면 타임아웃
)
save_data = BashOperator(
task_id="savedata",
bash_command="""
$SPARK_HOME/bin/spark-submit /home/centa/code/3kcal/dags/pyspark_pj3.py {{data_interval_start.strftime('%Y%m%d%H%M')}}
"""
)
start = EmptyOperator(task_id='start')
end = EmptyOperator(task_id='end')
start >> wait_logf >> save_data >> end
- task_id='wait_logf': 이 센서 작업의 고유 ID. Airflow의 그래프 및 로그에서 이 작업을 구분하는 데 사용.
- external_dag_id='predict_emotion': 외부 DAG의 ID. 즉, 이 작업은 "predict_emotion"이라는 이름의 다른 DAG에서 특정 작업이 완료될 때까지 대기.
- external_task_id='prediction': 외부 DAG에서 기다릴 특정 작업의 ID. 이 경우 prediction이라는 작업이 완료될 때까지 대기.
이 옵션은 선택 사항이므로, external_task_id를 지정하지 않으면 DAG 전체가 완료될 때까지 대기한다. - allowed_states=['success']: 외부 작업이 성공적으로 완료될 때만 다음 작업으로 넘어간다. 여기서 allowed_states는 외부 작업이 완료된 상태를 지정하며, 성공(success) 상태만 허용하고 있다.
- failed_states=['failed', 'skipped']: 외부 작업이 실패(failed)하거나 건너뛰어진(skipped) 경우, 이 센서 작업도 실패로 처리된다. 즉, failed 또는 skipped 상태가 발생하면 센서는 더 이상 대기하지 않고 실패 상태로 끝난다.
- timeout=300: 이 센서가 최대 300초(5분) 동안 대기할 수 있으며, 이 시간이 지나도 외부 DAG의 작업이 완료되지 않으면 타임아웃 에러가 발생
팀 프로젝트를 진행하면서...
좋은 점
- 원활한 커뮤니케이션: 프로젝트 진행 중 커뮤니케이션이 매우 원활했기 때문에, 각 단계에서 합의와 조율이 빠르게 이루어졌고, 이는 일정 준수에 큰 도움이 되었다.
- 협업 굿: 팀원들과의 역할 분담이 명확했고, 각자의 책임에 맞는 업무를 수행함으로써 프로젝트를 효율적으로 진행할 수 있었다.
- 문제 해결: 예상치 못한 이슈가 발생했을 때, 적극적으로 문제를 공유하고 논의하여 적절한 해결책을 찾을 수 있었다.
아쉬운 점
- 아키텍처 이해의 차이: 프로젝트 초기 단계에서 각 팀원 간에 아키텍처에 대한 이해 차이가 있어 일시적으로 혼란이 있었지만, 커뮤니케이션을 통해 차이를 해소하고 문제를 해결했다.
- 시간 관리: 예상보다 시간이 많이 소요된 작업들이 있었고, 그로 인해 일정이 조금 밀린 부분이 있었다. 이를 보완하기 위해 이후에는 더 구체적인 계획 수립이 필요할 것으로 보인다.
개선해야할 점
- 기술 숙련도 향상: Streamlit 등 새로운 툴을 사용하는 데 어려움을 겪었고, 에러 해결에 시간이 걸렸다. 향후 이러한 툴에 대한 숙련도를 높이고, 포트폴리오를 만들 때에도 활용할 수 있도록 더욱 익숙해질 필요가 있다.
- 초기 설계 명확화: 아키텍처 설계 단계에서 충분한 논의를 통해 모든 팀원이 같은 이해를 가질 수 있도록 하는 것이 중요하다. 이를 통해 불필요한 수정 작업을 줄일 수 있을 것이다.
- 피드백 주기적 수집: 프로젝트 도중에도 주기적으로 팀원 피드백을 수집하여, 개발 중간에라도 개선할 부분을 빠르게 반영하는 것이 좋을 것같다.
어플리케이션 시연
첫번째 페이지: 이용자가 유저ID와 리뷰를 입력해 데이터베이스로 전송

두번째 페이지: 유저ID와 number를 선택해 예측결과에 대한 코멘트와 실제 답을 입력
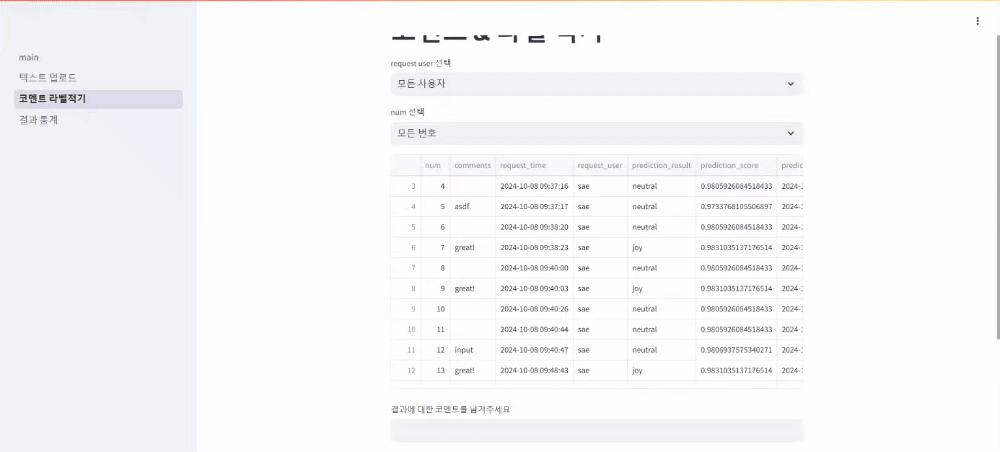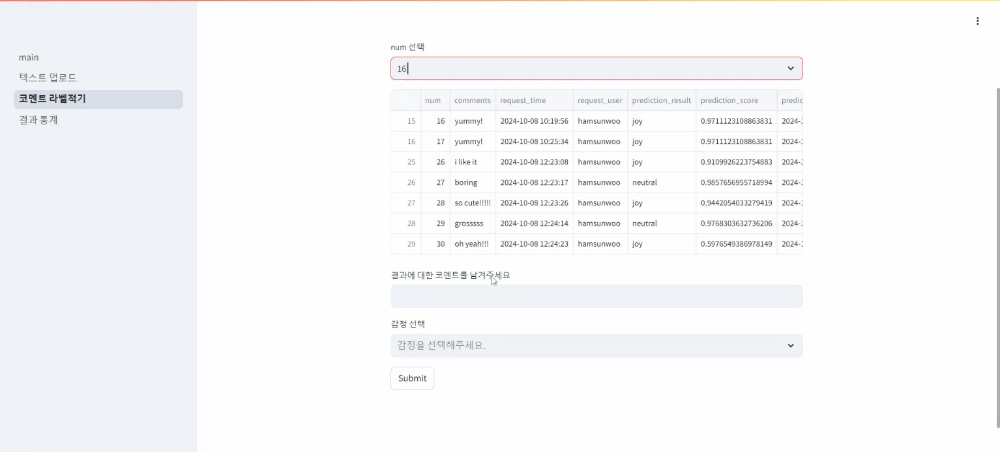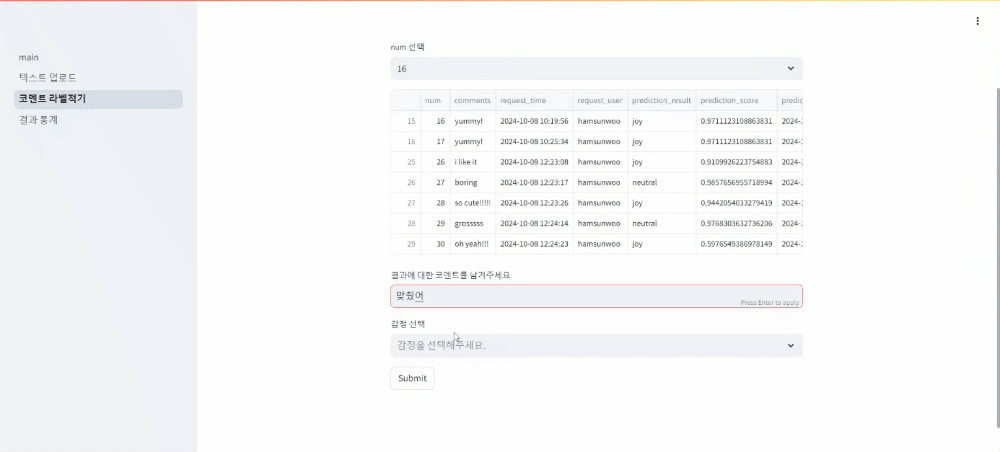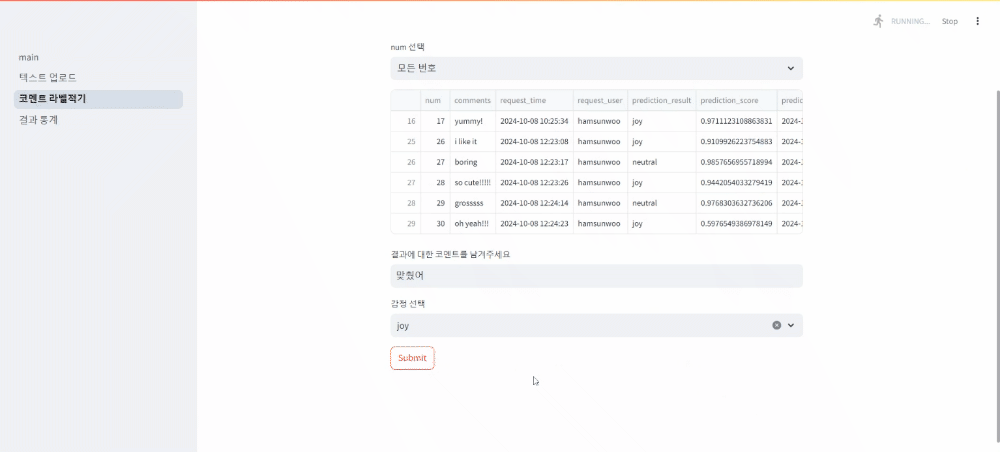
세번째 페이지: 위 두 페이지를 통해 형성된 데이터베이스에 대한 각종 통계 자료 확인

프로젝트 칸반보드
1일차 칸반보드
2일차 칸반보드
3일차 칸반보드

로드맵

세번째 팀프로젝트를 마치면서...
이전보다 훨씬 더 체계적으로 프로젝트를 진행할 수 있었다. 첫 번째, 두 번째 프로젝트에서는 무엇을 먼저 해야 할지 고민이 많았지만, 이번에는 자연스럽게 해야 할 일들이 머릿속에 그려졌다. 코드를 작성하는 것도 많이 익숙해졌고, 코드 최적화를 위해 다양한 방법을 시도하면서 문제 해결 능력도 더 나아졌다.
특히 이번 프로젝트에서는 팀 협업을 위해 GitHub의 PR과 issue 기능을 적극적으로 사용한 것이 큰 차이점이었다. 지난 프로젝트에서는 이 부분이 아쉬웠던 만큼 이번에는 더 신경 써서 활용했고, 그 결과 팀원들과의 소통이 훨씬 원활해졌다. 개선해 나가는 과정을 보며 스스로 뿌듯함을 느낄 수 있었고, 이번 경험을 통해 더 나은 협업 능력을 쌓을 수 있었다.
프로젝트를 진행하며 느낀 점은, 코드 작성 뿐만 아니라 협업 도구와 방법론을 잘 활용하는 것이 팀 프로젝트의 성공을 좌우한다는 것이다. 이를 통해 앞으로 더 발전할 수 있을 것이라는 자신감을 얻었다.
'데이터 엔지니어링' 카테고리의 다른 글
| 데이터엔지니어 부트캠프 - 젠킨스(Jenkins) 이해하기&실행해보기 (16주차) (0) | 2024.10.22 |
|---|---|
| 데이터엔지니어 부트캠프 - 스프링부트(Springboot) 이해하기 (15주차) (3) | 2024.10.20 |
| 데이터엔지니어 부트캠프 - 사용자 웹페이지에 hotdog 판별하는 API 기능 연결하기 (0) | 2024.10.02 |
| 데이터엔지니어 부트캠프 - Tensorflow 버전 호환 문제 해결하기 + 딥러닝 관련 패키지 호환문제 해결하기 (12주차) (1) | 2024.09.28 |
| 데이터엔지니어 부트캠프 - FastAPI로 파일 업로드 기능 구현하고 파일을 업로드할 때마다 DB에 저장시키기 2탄 with Docker (12주차) (0) | 2024.09.28 |



