
imhamburger 님의 블로그
판다스(Pandas) - Partition_cols 이해하기 본문
partition_cols 을 이용하면 데이터 용량을 줄일 수 있다.
partition_cols은 일반적으로 데이터프레임을 저장할 때 특정 열(Column)을 기준으로 데이터를 분할하는 데 사용되는 인수이다. partition_cols은 보통 Parquet 또는 ORC 파일 형식 저장에서 사용되며, 데이터를 여러 파일 또는 폴더로 나눠서 저장한다.
이렇게하면, 방대한 데이터가 있을 때 더 관리하기 쉬워지고 데이터를 빠르게 찾아 로드할 수 있다.
게다가 큰 장점은 용량이 적다는 것!
아래는 실제로 partition_cols을 사용하여 저장한 데이터와 그렇지 않은 데이터의 용량 크기 차이를 보여준다.
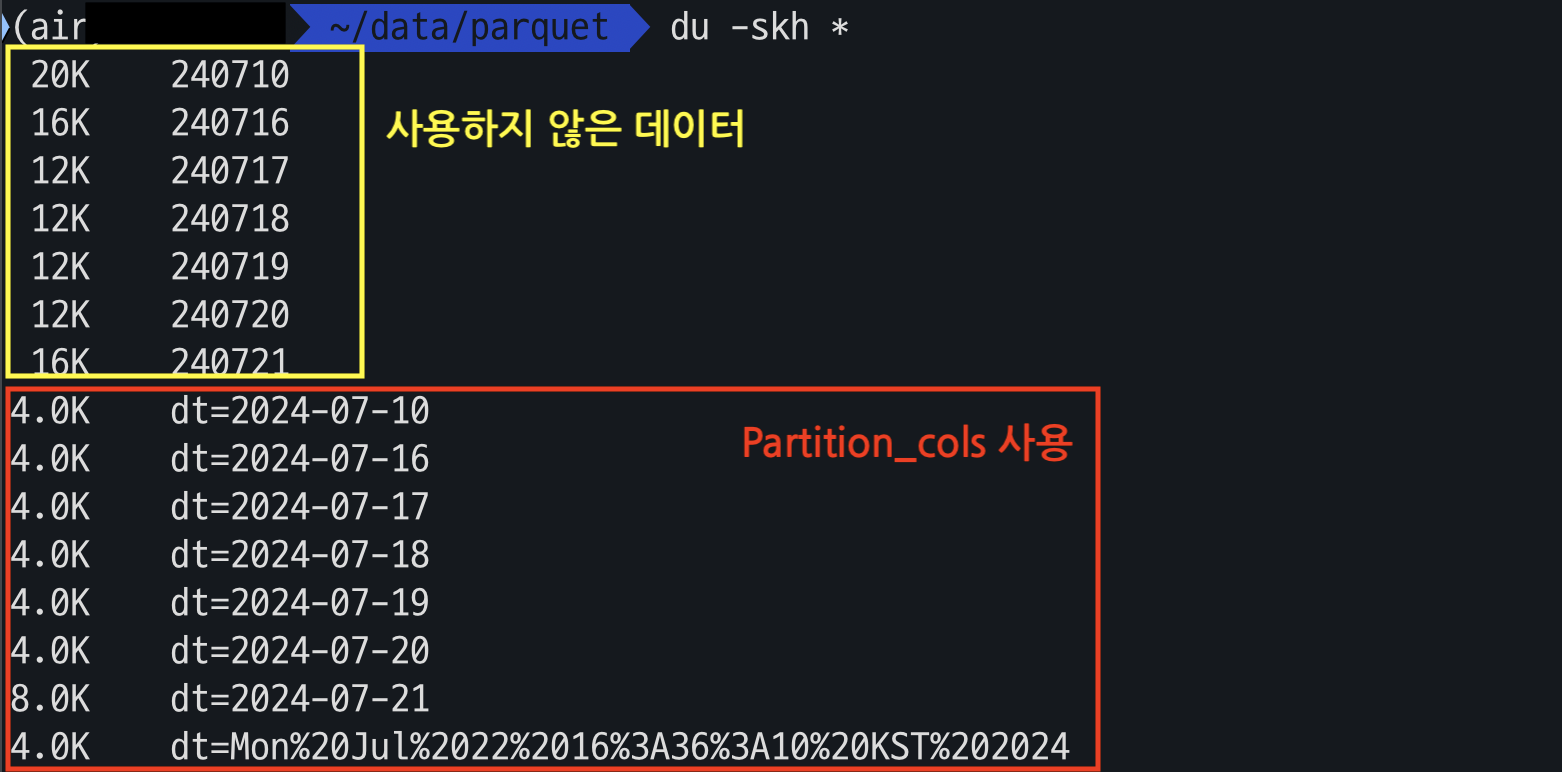
Partition_cols을 사용하는 방법은 간단하다.
{데이터테이블명}.to_parquet('{저장할 파일경로}',partition_cols=['{열이름}'])어떤 열을 기준으로 분할할 것인지 {열이름}을 적어주면 된다. 보통 날짜를 기준으로 분할하는데 연도별 / 월별로 분할한다.
예시
df.to_parquet('~/tmp/partition_parquet',partition_cols=['dt'])위 코드는 'dt'라는 이름을 가진 열을 기준으로 데이터를 분할한 것이다.
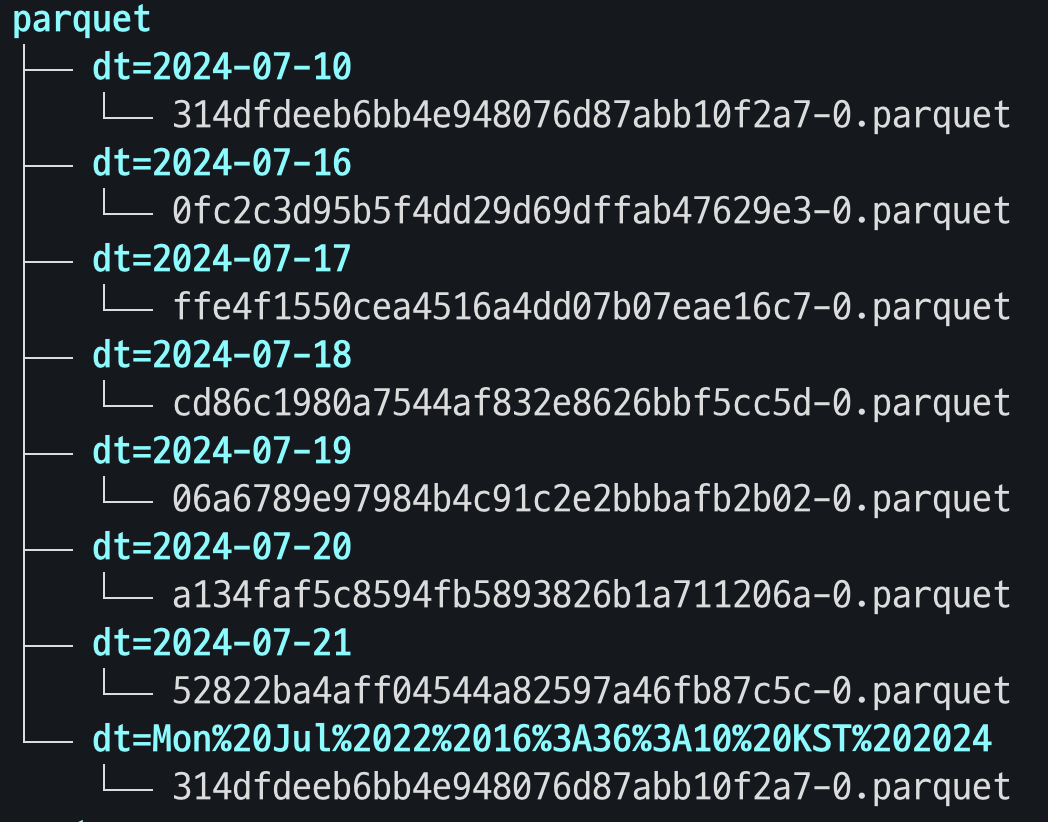
Parquet 형식으로 잘 들어온 것을 확인할 수 있다.
파일을 불러올 때도 간단하다.
{변수명} = pd.read_parquet('{확인하고싶은 데이터 경로}')
만약, 1980-01-01 날짜의 데이터만 보고싶다면 해당 데이터 파일경로만 입력해 확인할 수 있다. (아래 예시)
rdf = pd.read_parquet('~/tmp/partition_parquet/dt=1980-01-01/a8fa0fbb23c0499fb1e77aa60a02693c-0.parquet')
출력결과

Partition_cols은 빅데이터를 저장하고 관리할 때 아주 유용하다!
'판다스(Pandas)' 카테고리의 다른 글
| Pandas join으로 데이터에 이미 존재하는 ID가 있으면 append 하기 (0) | 2025.11.16 |
|---|---|
| PostgreSQL의 JSON 타입 컬럼을 Pandas로 읽을 때 (0) | 2025.10.19 |
| 데이터엔지니어 부트캠프 - 영화 박스오피스 데이터 ETL(Extraction / Transform / Load) (7월의 기록) (1) | 2024.08.04 |
| 판다스(Pandas) - csv파일 불러오기, unicode 에러 해결하기 (0) | 2024.07.25 |
'판다스(Pandas)' Related Articles
more


