

imhamburger 님의 블로그
데이터엔지니어 부트캠프 - 로그데이터를 카프카를 이용해서 s3에 적재하기 (21주차) 본문
파이널 프로젝트에서 우리의 서비스를 이용하는 사용자 로그를 s3에 적재하는 것을 설계했었다.
로그데이터는 실시간으로 찍히기 때문에 Apache Kafka를 이용하면 딱! 이겠다라는 생각이 들었다.
로그데이터를 저장하려고하는 이유는,
각 부서가 데이터 기반 의사결정을 내릴 수 있도록 지원하기 위해, 대시보드에서 실시간 데이터를 시각화하고 활용할 수 있게 만들기 위함이다.
이를 위해 로그 데이터를 실시간으로 수집하고 적재하는 안정적인 파이프라인이 필요하다.
Apache Kafka는 높은 처리량과 낮은 지연 시간을 보장하며, 로그 데이터의 스트리밍 처리에 적합한 도구로, 실시간 데이터 수집과 처리에 딱 맞는 솔루션이라고 생각했다.
따라서, 로그데이터 적재 설계는 다음과 같다.
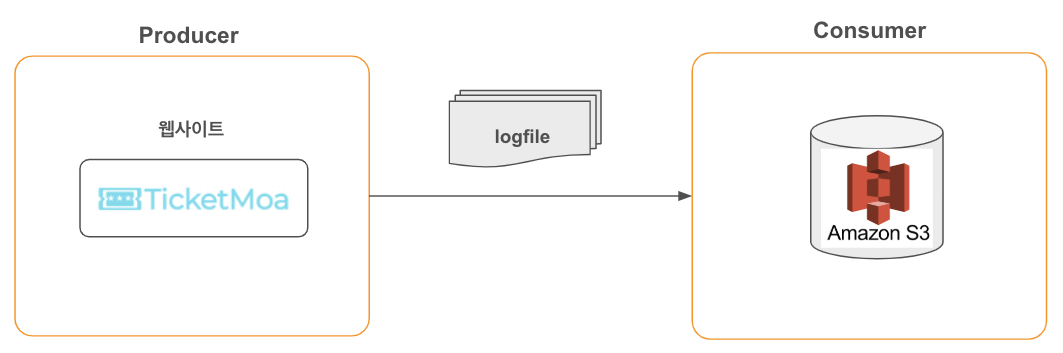
1. 우선 나는 로그를 생성하는 기능을 먼저 만들었다. 여기서 카프카 프로듀서가 메세지를 전달한다.
log_handler.py
from kafka import KafkaProducer
import logging
import os
import json
from datetime import datetime
from logging.handlers import RotatingFileHandler
# 로거 설정
logger = logging.getLogger()
logger.setLevel(logging.INFO) # 기본 로그 레벨 설정
class JsonFormatter(logging.Formatter):
def format(self, record):
log_message = {
"timestamp": datetime.now().isoformat(),
"level": record.levelname,
"message": record.getMessage()
}
return json.dumps(log_message, ensure_ascii=False)
# Kafka 프로듀서 설정 (전역에서 한 번만 설정)
from dotenv import load_dotenv
# .env 파일을 로드하여 환경 변수를 읽기
load_dotenv()
# Kafka 서버 환경 변수에서 값을 읽음
KAFKA_SERVER = os.getenv("KAFKA_SERVER")
producer = KafkaProducer(
bootstrap_servers=KAFKA_SERVER,
acks='all',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# 로그 이벤트 함수 정의
def log_event(user_id: str, device: str, action: str, **kwargs):
# 로그 메시지 생성
log_message = {
"timestamp": datetime.now().isoformat(),
"user_id": user_id,
"device": device,
"action": action,
**kwargs
}
# Kafka에 로그 메시지 전송
producer.send('logs', log_message)
producer.flush()
print("로그 데이터 전송 완료!")
# 예시 실행
# log_event(user_id="12345", device="Mozilla/5.0", action="login")
결과
{"timestamp": "2024-12-05T15:47:13.125306", "level": "INFO", "message": "{'timestamp': '2024-12-05T15:47:13.125192', 'user_id': '12345', 'device': 'Mozilla/5.0', 'action': 'login'}"}
{"timestamp": "2024-12-05T15:47:13.125432", "level": "INFO", "message": "{'timestamp': '2024-12-05T15:47:13.125372', 'user_id': '67890', 'device': 'Safari/13.0', 'action': 'search', 'region': 'Seoul'}"}
왜 JSON형식으로 선택했나?
나의 경우, 로그데이터를 JSON 형식으로 지정하였다.
이유는 원래 " , " 쉼표로 로그데이터를 저장하려 하였으나 확장성을 고려하니 Key-Value 형식인 JSON 형식이 괜찮아보였다.
만약, " , "로 저장했을 시 추후에 컬럼 하나가 추가되거나 중간에 무언가가 삭제되는 데이터가 있다면..
데이터의 정합성과 가독성이 크게 저하될 가능성이 있다. 쉼표로 구분된 데이터(CSV 형식)는 정형화된 구조에서 효율적일 수 있지만,
컬럼 추가나 변경이 발생할 경우 데이터 파싱 과정에서 오류가 발생하거나 기존 데이터와 호환되지 않을 가능성이 높다.
그런면에서 JSON은 Key-Value 구조로 되어 있어, 새로운 필드를 추가하더라도 기존 데이터에 영향을 주지 않는다.
결론적으로, JSON 형식은 확장성과 유연성을 고려할 때 최적의 선택이며, 추후 데이터 활용과 유지보수에도 유리한 구조를 제공한다.
이를 바탕으로 로그 데이터를 수집, 적재, 분석하는 전체 파이프라인이 보다 안정적이고 확장 가능하도록 설계할 수 있다.
2. API로 호출된 데이터를 저장하고싶은 것만 로그데이터로 저장시킨다.
tickets.py
current_timestamp = datetime.now().isoformat()
device = request.headers.get("User-Agent", "Unknown")
user_id = request.headers.get("user_id", "anonymous") # user_id가 없으면 "anonymous"로 기본값 설정
try:
log_event(
current_timestamp=current_timestamp,
user_id=user_id, # 헤더에서 받은 user_id 사용
device=device, # 디바이스 정보 (User-Agent 또는 쿼리 파라미터)
action="search", # 액션 종류: 'Search'
category=category, # 카테고리
region=region, # 지역
keyword=keyword
)
print("Log event should have been recorded.")
except Exception as e:
print(f"Error logging event: {e}")
기본적으로 유저의 id 혹은 device 정보는 header값에서 가져온다.
3. 프로듀서가 이 내용들을 보내고 컨슈머에서 받아 s3에 적재한다.
consumer.py
from kafka import KafkaConsumer
import json
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import boto3
import os, time
from io import BytesIO
from dotenv import load_dotenv
# .env 파일을 로드하여 환경 변수 읽기
load_dotenv()
KAFKA_SERVER = os.getenv("KAFKA_SERVER")
# Kafka consumer 설정
consumer = KafkaConsumer(
'logs',
bootstrap_servers=KAFKA_SERVER,
group_id='log-consumer-group',
enable_auto_commit=False, # 수동 오프셋 커밋 설정
auto_offset_reset='latest',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# S3 클라이언트 설정
s3 = boto3.client('s3',
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY"),
region_name="ap-northeast-2"
)
def consume_and_save_to_s3(batch_size=100, timeout=10):
log_messages = []
start_time = time.time()
while True:
for message in consumer:
log_messages.append(message.value)
print(f"토픽: {message.topic}, 메시지: {message.value}")
# 배치 크기가 되거나, 지정한 시간이 경과하면 S3에 업로드
if len(log_messages) >= batch_size or time.time() - start_time >= timeout:
# 로그 메시지를 pandas DataFrame으로 변환
df = pd.json_normalize(log_messages) # JSON을 DataFrame으로 변환
# DataFrame을 Parquet 형식으로 변환
table = pa.Table.from_pandas(df)
# 메모리 버퍼에 Parquet 파일을 저장
buffer = BytesIO()
pq.write_table(table, buffer)
buffer.seek(0) # 버퍼의 처음으로 이동
# S3에 Parquet 파일 업로드
timestamp = time.strftime("%Y-%m-%d_%H-%M") # timestamp로 파일명 생성
s3.put_object(
Bucket='t1-tu-data',
Key=f'search_log/{timestamp}.parquet',
Body=buffer
)
print(f'로그가 S3에 업로드되었습니다: search_log/{timestamp}.parquet')
# 배치 후 초기화
log_messages = []
start_time = time.time() # 시간 초기화
consumer.commit()
time.sleep(0.5)
if __name__ == '__main__':
consume_and_save_to_s3(batch_size=100, timeout=10)
실시간 이벤트(로그)가 발생할 때마다 카프카 프로듀서로 보내지고 컨슈머에서 이를 받아 s3에 parquet 파일로 변환하여 저장시킨다.
결과
aws s3 ls logs/
2024-12-05 17:01:09 5753 2024-12-05T08-01-08.478185.parquet
2024-12-05 17:01:58 5753 2024-12-05T08-01-57.330867.parquet
parquet 파일을 열었을 때는 다음과 같다.
timestamp user_id device ... category region keyword
0 2024-12-05T08:01:08.478185 anonymous Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7... ... 연극 None None
개선해야할 점?
이벤트가 발생할때마다 저장시키기 때문에 작은 로그 파일을 하나씩 처리하면 I/O 부하가 커질 수 있다.
따라서, 여러 개의 로그를 묶어서 처리하는 방법은 성능을 최적화하고 시스템 리소스를 효율적으로 활용할 수 있도록 해야할 것 같았다.
해결방법으로 Kafka Consumer에서 메시지를 일정 수 또는 일정 시간 동안 묶어서 처리하는 방식을 추가하였다.
나의 에러 리포트
에러 1) mongoDB 연결 안되는 오류
File "/Users/seon-u/TU-tech/database/.venv/lib/python3.11/site-packages/pymongo/helpers_shared.py", line 247, in _check_command_response
raise OperationFailure(errmsg, code, response, max_wire_version)
pymongo.errors.OperationFailure: bad auth : authentication failed, full error: {'ok': 0, 'errmsg': 'bad auth : authentication failed', 'code': 8000, 'codeName': 'AtlasError'}
발생이유
client = AsyncIOMotorClient("mongodb+srv://summ~~~
mongodb+srv 를 읽지못해 생기는 오류이다. (사전에 네트워크, 권한 확인 필요)
해결방법
pip install dnspython
dnspython은 Python에서 DNS(Domain Name System) 관련 작업을 수행할 수 있도록 도와주는 모듈이다.
이 모듈은 DNS 질의, DNS 레코드 처리, DNS 서버 설정 등을 수행하는 데 사용된다.
2) FastAPI를 yaml로 compose up 할 때 모듈을 찾지 못하는 오류
File "/code/src/database/main.py", line 2, in <module>
from database.routers import tickets # tickets 라우터를 포함한 모듈
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'database'
발생이유
yaml로 compose up 할 때 파이썬 파일 path를 읽지못해 생기는 오류이다.
해결방법
PYTHONPATH 를 yaml에 명시해줘야 한다.
services:
fastapi-app:
build: .
ports:
- "7777:7777" # 호스트와 컨테이너의 포트 매핑
volumes:
- ./src:/code/src # 로컬 src 폴더와 컨테이너의 /code/src 폴더를 연결
env_file:
- .env # .env 파일에서 환경 변수 가져오기
environment:
- PYTHONPATH=/code/src # ---------------------> src 디렉토리를 PYTHONPATH에 추가
networks:
- api-network
일주일을 보내면서...
파이널 프로젝트를 시작한 지도 벌써 3주가 되었다. 그동안 로그 데이터의 기초적인 틀을 마련하고, 데이터의 수집과 저장 과정을 설계했다.
처음에 로그데이터를 어떻게 수집하고 저장하는지 감이 잘 잡히지 않았었는데, 강사님께 여쭤보고 이것저것 구글링하면서 감을 잡을 수 있었다.
프로젝트를 진행하며 예상치 못했던 어려움도 많았다. 특히, 데이터를 저장하는 방식에서 효율성과 확장성을 동시에 고려해야 한다는 점에서 많은 고민이 필요했다. 처음에는 단순히 데이터를 쌓는 데만 집중했지만, 실제로는 수집된 데이터를 어떻게 활용할 수 있을지까지 염두에 두고 설계해야 한다는 것을 배웠다.
지난번에 로우데이터를 s3에 적재할 때 카프카를 썼었는데 그때는 카프카가 잘 동작하지 않아 애를 먹었었다...
근데 이번에 로그데이터 저장 기능을 구현하면서 다시 한번 카프카를 썼는데 이제 뭔가 카프카에 대해 조금은 알 것 같았다. 로우데이터쪽을 다시 다룰 때 참고해야겠다.
앞으로 나의 방향
데이터 엔지니어링을 하면서 코딩을 하는 것보다 아키텍쳐를 설계하고 그 안에서 어떻게 효율적으로 돌아가게 할 것인가가 가장 어려운 것 같다. 하지만 이런 과정을 통해 점점 문제를 정의하고 해결하는 능력이 길러지고 있다고 느낀다. 파이프라인을 구성하면서 어떤 데이터를 어떤 형식으로 처리할지 결정하고, 이를 통해 최적의 결과를 도출하기 위한 고민을 하는 과정이 재미있기도 하고... 아직은 어려워서 그런지 머리가 아프다...
'데이터엔지니어 부트캠프' 카테고리의 다른 글
| 데이터엔지니어 부트캠프 - MongoDB jwt토큰 decode 하여 user_id 불러오기 (22주차) (1) | 2024.12.15 |
|---|---|
| 데이터엔지니어 부트캠프 - MongoDB에 적재할 때 중복값 처리하기 (0) | 2024.12.10 |
| 데이터엔지니어 부트캠프 - 에어플로우와 s3 연결하기 + mongodb 연결하기 (11월의 기록) (0) | 2024.12.01 |
| 데이터엔지니어 부트캠프 - Redis Cache로 에어플로우 배치돌렸을 때 마지막 번호부터 실행하게 하기 (20주차) (0) | 2024.12.01 |
| 데이터엔지니어 부트캠프 - 도커 컨테이너 안에 Chrome 설치하기 + 컴포즈로 에어플로우 실행하기 (19주차) (2) | 2024.11.23 |


